
A decision-space model explains context-specific decision-making
Abstract
Optimal decision-making requires consideration of internal and external contexts. Biased decision-making is a transdiagnostic symptom of neuropsychiatric disorders. We created a computational model demonstrating how the striosome compartment of the striatum constructs a context-dependent mathematical space for decision-making computations, and how the matrix compartment uses this space to define action value. The model explains multiple experimental results and unifies other theories like reward prediction error, roles of the direct versus indirect pathways, and roles of the striosome versus matrix, under one framework. We also found, through new analyses, that striosome and matrix neurons increase their synchrony during difficult tasks, caused by a necessary increase in dimensionality of the space. The model makes testable predictions about individual differences in disorder susceptibility, decision-making symptoms shared among neuropsychiatric disorders, and differences in neuropsychiatric disorder symptom presentation. The model provides evidence for the central role that striosomes play in neuroeconomic and disorder-affected decision-making.
Article type: Research Article
Keywords: Biophysical models, Neural circuits, Motivation
Affiliations: https://ror.org/04d5vba33grid.267324.60000 0001 0668 0420Computational Science Program, University of Texas at El Paso, El Paso, TX USA; https://ror.org/04d5vba33grid.267324.60000 0001 0668 0420Department of Biological Sciences, University of Texas at El Paso, El Paso, TX USA; https://ror.org/04a9tmd77grid.59734.3c0000 0001 0670 2351Department of Psychiatry, Department of Pharmacological Sciences, Icahn School of Medicine at Mount Sinai, New York, NY USA; https://ror.org/042nb2s44grid.116068.80000 0001 2341 2786Artificial Intelligence Laboratory, Department of Computer Science, Massachusetts Institute of Technology, Cambridge, MA USA; https://ror.org/03taz7m60grid.42505.360000 0001 2156 6853Ming Hsieh Department of Electrical and Computer Engineering, Viterbi School of Engineering, University of Southern California, Los Angeles, CA USA; https://ror.org/03vek6s52grid.38142.3c000000041936754XDepartment of Biomedical Informatics, Harvard Medical School, Cambridge, MA USA; https://ror.org/04zjtrb98grid.261368.80000 0001 2164 3177Department of Mathematics and Statistics, Old Dominion University, Norfolk, VA USA; https://ror.org/00fq5cm18grid.420090.f0000 0004 0533 7147National Institute on Drug Abuse, Baltimore, MD USA; https://ror.org/04d5vba33grid.267324.60000 0001 0668 0420Department of Psychology, University of Texas at El Paso, El Paso, TX USA; https://ror.org/04a9tmd77grid.59734.3c0000 0001 0670 2351Center for Translational Medicine and Pharmacology, Icahn School of Medicine at Mount Sinai, New York, NY USA
License: © The Author(s) 2025 CC BY 4.0 Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Article links: DOI: 10.1038/s41467-025-61466-x | PubMed: 40813575 | PMC: PMC12354707
Relevance: Moderate: mentioned 3+ times in text
Full text: PDF (2.8 MB)
Introduction
Decision-making is altered in neuropsychiatric disorders affecting the basal ganglia1. A range of experimental evidence links balances between the striatal compartments and connected brain regions to decision-making function and dysfunction2–6. Understanding these intricate interactions will be crucial for designing next-generation treatments.
Striatal neurons can be categorized into groups via neurochemistry and connectivity, including the striosome and matrix compartments4,7. Striosomal spiny projection neurons (sSPNs) make up ~10–15% of the striatum and matrix spiny projection neurons (mSPNs) the remaining ~85–90%8,9 (for acronyms, see Table 1). New technologies, including recording, targeting methods, and genetically engineered mice, have enabled important new discoveries about differential roles for striosomes and matrix in decision-making3,10–19, including in disorders2,4. Further, both sSPNs and mSPNs belong to either the direct pathway (dsSPNs and dmSPNs), identified by D1 receptor expression, or the indirect pathway (isSPNs and imSPNs) identified by D2 receptor expression4,20. Notably, dsSPNs, to a greater extent than dmSPNs, project to regions which influence midbrain dopamine release via a subcircuit conserved across species8,16,21–24 (Fig. 1, Supplementary Table 1). Thus, dsSPNs, isSPNs, dmSPNs, and imSPNs appear to have different circuit roles16,20, raising the possibility they each play a distinct functional role during decision-making (see Supplementary Note 1).
Table 1: Terminology
| Term | Definition |
|---|---|
| GPi | Globus pallidus internus |
| GPe | Globus pallidus externus |
| LHb | Lateral habenula |
| RMTg | Rostromedial tegmental nucleus |
| daSNC | Dopaminergic neurons of the substantia nigra compacta |
| FSI | Striatal fast-spiking Interneuron |
| SPN | Striatal projection neuron |
| sSPN | Striosomal striatal projection neuron |
| mSPN | Matrix striatal projection neuron |
| dsSPN | Direct pathway striosomal striatal projection neuron |
| isSPN | Indirect pathway striosomal striatal projection neuron |
| dmSPN | Direct pathway matrix striatal projection neuron |
| imSPN | Indirect pathway matrix striatal projection neuron |
| BG | Basal ganglia |
| Decision-dimension | An axis of the coordinate system with which SPNs (dsSPNs, isPSNs, dmSPNs, imSPNs) process cortical activity. Subpopulations of SPNs (for each dsSPNs, isSPNs, dmSPNs, imSPNs) encode data along different decision-dimensions. Cortical activity is linearly mapped to this basis of decision-dimensions such that the activity of a single cortical neuron is no longer encoded by a single SPN. Certain decision-dimensions might correspond more predominantly, for instance, to reward level, cost level, or novelty level, as encoded across multiple cortical neurons. Decision-dimensions are modeled as the principal components of cortical activity. For additional details, see Decision-dimensions and decision-space, Methods. |
| Decision-space | The subspace produced by the decision-dimensions which are selected by the circuit to be used during a decision. Decision-space is formed when dopamine releases to matrix striatal projection neurons (dmSPNs and imSPNs), signaling that certain decision-dimensions are important and others are unimportant, and therefore can be excluded from the subspace. |
| Action value | Value assigned by the circuit to an action |
| Inaction value | Value assigned by the circuit for refraining from an action |
| Prediction error | The difference between expected and observed information along a data axis (for instance, reward prediction error, punishment prediction error, or novelty prediction error) |
| Circuit activity | The set of average activities of each circuit element during a decision |
| Advantage | The degree to which a circuit activity is preferred. Used in our analysis of the change in circuit activity between trials. |
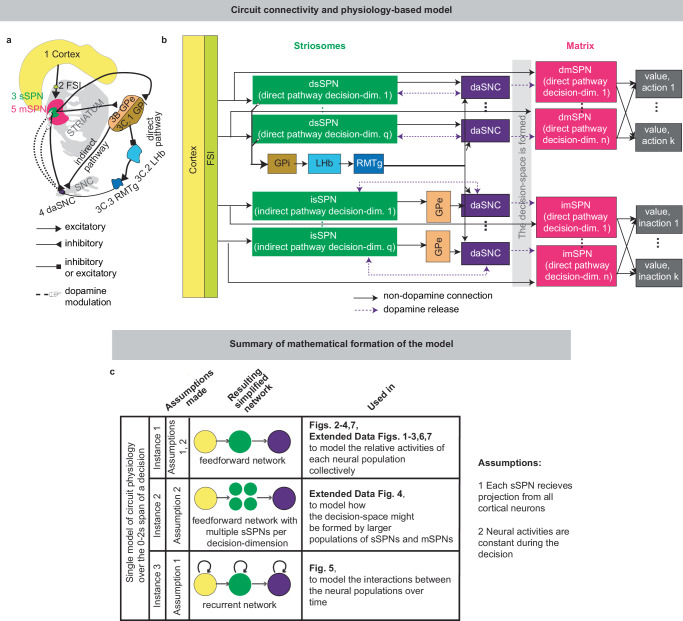
Models of cortico-striatal-basal ganglia-thalamic regions often examine the direct, indirect, and, more recently, the hyperdirect pathways25,26 to elucidate how they interact during different cognitive processes like decision-making, action selection, and learning. These models explore potential circuit functionality in a variety of ways including: exploring how cortico-striatal neurons may utilize general features to facilitate adaptable/flexible decision-making27, examining how this circuit shifts reward-seeking based on internal states28, explaining how basal ganglia structures exercise nuanced control over action selection despite subsequent regions containing fewer neurons29, and exploring the role of direct and indirect pathway competition during action selection30,31. Another approach taken when modeling the basal ganglia is to explore how dopamine and basal ganglia corticostriatal loops influence basal ganglia functions like decision-making, learning, and action selection. One example is where corticostriatal loops modulate dopaminergic activity/plasticity where dopamine signals vector-based error signals associated with different task-related factors32. Many of these models, while exploring important ideas for cortico-basal ganglia-thalamic interactions/functions during decision-making, learning, and action selection, do not account for differences between the striatal matrix and striosomal compartments. Without the striosome versus matrix distinction, they do not capture the interplay between dopamine and the striatum in a precise way. The dopaminergic interplay is especially important for the study of neuropsychiatric disorders, because disorders that differentially affect the direct versus indirect pathways33 have been found to also affect striosomes versus matrix differently2, suggesting that attention to all four dsSPN/isSPN/dmSPN/imSPN compartments is necessary for an accurate understanding of decision-making in normal and disordered states.
To close this gap, we formed a model that accounts for striosome versus matrix subdivisions, including the selective modulation of midbrain dopamine by striosomes (Fig. 1, Supplementary Fig. 1). From our physiological model arises the concept of a “decision-dimension”, our term for an axis along which the modeled circuit encodes decision-related information (Fig. 2, Supplementary Fig. 2; for terminology, see Table 1). During a decision, decision-dimensions are prioritized in a context-dependent manner, forming a mathematical “decision-space.” We present evidence, via our analysis of neural recordings and our models of findings from experimental literature, for the core tenets of our model: that subpopulations of SPNs encode information along decision-dimensions, that a decision-space is formed, and that the decision-space changes across contexts (Figs. 3,4, Supplementary Figs. 3–6). Then we demonstrate the power of the model to explain a range of physiological and behavioral phenomena, including the roles of the indirect/direct pathway and reward prediction error (RPE) (Fig. 5, Supplementary Fig. 7). Finally, we speculate how the model might explain behavioral phenomena observed in psychiatry (Figs. 6, 7, Supplementary Figs. 8, 9) and suggest future experiments (Supplementary Fig. 10).
Results
Model description
Our model describes how physiological interactions between elements of a striosome-centered circuit inform decision-making (Fig. 1a, b, for extended reasoning behind our choice of circuit elements, see Supplementary Note 2; for extended documentation of the model, see Analyzed instances of the model, Methods). Depending on the purpose of our analysis, we either consider the dynamics of the circuit over the span of the decision or assume, for simplicity, that the circuit elements express constant activities across the short decision period (Fig. 1c, Supplementary Fig. 1).
In the model, striatum-projecting cortical neurons that encode mixed information serve as the input to the modeled circuit. We assume for the purpose of our model that the information passed from the cortex to each striatal compartment is roughly similar (in actuality, there is much overlap with some differences, see Supplementary Table 1 and Supplementary Note 3). The cortical neurons synapse on subpopulations of proximate SPNs which have been found to each encode distinct information34. During this process, fast spiking interneurons (FSIs) perform a normalization operation (Supplementary Fig. 2a). Mathematically, we represent this as a matrix WP dictating cortex-SPN connection weights for each pathway P (direct or indirect) mapping cortical activity xP to the coordinate space of sSPNs, where it undergoes divisive normalization by FSI activity cP and a shift in activity bsSPN to form sSPN activity ssSPN,P:
\[
{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}=\frac{1}{{c}_{P}}{{{{\bf{W}}}}}_{P}^{{{{\bf{T}}}}}{{{{\bf{x}}}}}_{P}+{b}_{{{{\rm{sSPN}}}}}
\]
Information from sSPNs is then passed to dopaminergic neurons of the substantia nigra compacta (daSNC). daSNC neurons, like sSPNs, have been shown to be organized topologically into subpopulations that each encode distinct information35. Experimental evidence suggests that signals are passed from sSPN subpopulations to daSNC neurons in three ways (see Supplementary Table 1): A (dsSPN→daSNC). Subpopulations of dsSPNs inhibit daSNC subpopulations directly via dendrite bouquets36. Thus, in our model, each dsSPN subpopulation inhibits a corresponding daSNC subpopulation. B (isSPN → GPe→daSNC). isSPNs send signals to daSNC neurons via GPe16, which inhibit daSNC subpopulations. Thus, in our model, each isSPN subpopulation disinhibits a corresponding daSNC subpopulation. C (dsSPN → GPi → LHb → RMTg→daSNC). GPi integrates signals from many sSPN subpopulations through synapses that release both GABA and glutamate37, and the LHb, when activated by GPi, powerfully inhibits multiple of the dopaminergic subpopulations via RMTg38,39. So, in our model, shifts in this pathway lead to a shift across all daSNC subpopulations. Mathematically, we represent the three circuits as daSNC combining activity from sSPNs SsSPN,P (with connection weights \({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}\) corresponding to each decision-dimension i and pathway P) with RMTg activity, GPe activity \({z}_{{{{\rm{GPe}}}},P}\) (only for the indirect pathway), and an additive shift \({z}_{{{{\rm{daSNC}}}},i,P}\):
\[
{{{{\rm{daSNC}}}}}_{i,P}=\frac{1}{1+\exp ({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}\cdot ({{{{s}}}}_{{{{\rm{s}}}}{{{\rm{S}}}}{{{\rm{P}}}}{{{\rm{N}}}},i,P}+{z}_{{{{\rm{GPe}}}},P})+{{{\rm{RMTg}}}}-{z}_{{{{\rm{daSNC}}}},i,P})}
\]
In addition to sSPNs, there are subpopulations of mSPNs, termed matrisomes4, that densely surround sSPN subpopulations. In our model, we hypothesize that these sSPN and mSPN subpopulations communicate with one another via dopamine release from the corresponding daSNC subpopulation (there are other sSPN→mSPN connections that we do not model that play more local roles, see Supplementary Note 4). There are multiple groups of these functionally connected sSPNs, daSNCs, and mSPNs. In the model, when a daSNC subpopulation is active, dopamine is released to the corresponding sSPN and mSPN subpopulations, resulting in enhanced or inhibited mSPN reception of cortical signal among the subpopulations, as shown in experimental work40. Mathematically, mSPN activity is defined similarly to sSPN activity, but for a diagonal matrix SP corresponding to the dopamine release that probabilistically defines the decision-space, with \({{\mathrm{P}}}({{\mathbf{S}}}_{P,{\mathrm{ii}}}=1) \;=\; {{\mathrm{daSNC}}}_{i,P}\):
\[
\begin{array}{c}{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}=\frac{1}{{c}_{P}}\end{array}{{{{\bf{S}}}}}_{P}{{{{{\bf{W}}}}}_{P}}^{{{{\bf{T}}}}}{{{{\bf{x}}}}}_{P}
\]
mSPNs have been found to be primarily involved in motor functions, projecting to regions including the GPi, SNr, and then to brainstem motor programs41. SPN activity (which is predominantly mSPN) has been shown to contribute to action selection and initiation42. The direct pathway has generally been implicated in promoting actions and the indirect pathway in preventing actions43. So, in our model, the output of the mSPN circuit is the definition of action values (the value of performing various actions, encoded by the direct pathway) and inaction values (the value of refraining from those actions, encoded by the indirect pathway) by mSPN signals on route to downstream regions. Mathematically, values vj,P (for each action/inaction j, pathway P) are defined based on mSPN activity, internal coefficients βj,P, and priors αj,P (which are set to arbitrary values that are constant across analyses, see Common parameters, Rationale behind parameter choices, Methods):
\[
{v}_{j,P}=\frac{1}{1+\exp (-{{{{\mathbf{\beta }}}}}_{j,P}\,{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}-{\alpha }_{j,P})},
\]
Based on these values, actions are either performed or refrained from over time. We model this using a Merton process model44 where the first process to hit a threshold is enacted (direct pathway) or refrained from (indirect pathway). This model functions similarly to a drift-diffusion model45, which has been used to model decisions including in the basal ganglia46, but is scaled to the case where more than two actions can be taken. See Defining choice, Methods.
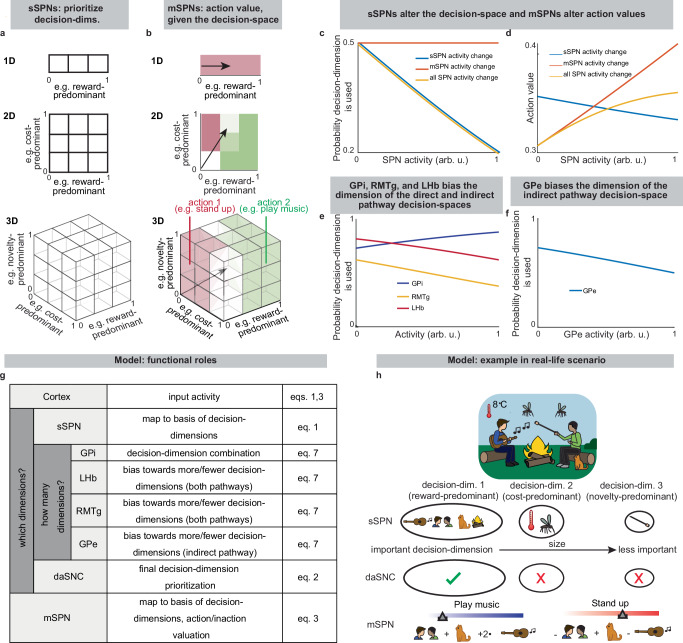
Thus, our model is constructed based on the anatomy and physiology of the striosome-centered circuit. The physiological description also produces a simple and convenient geometric interpretation (Fig. 2a, b). If we let each SPN and daSNC subpopulation encode the principal components of cortical activity, such as could be learned via a modified Oja’s rule47, then the columns of wP become orthogonal. So, each SPN subpopulation can be thought of as encoding information along an axis of Euclidean space. We term these axes “decision-dimensions” and have evidence that they correspond to constructs such as reward, cost, or novelty (discussed in more detail below). Because, in the model, dsSPNs and isSPNs form subpopulations separately, there is one set of decision-dimensions corresponding to the direct pathway and another set corresponding to the indirect pathway. We suggest that when dopamine is released to SPNs, selectively enhancing the reception of the cortical signal, decision-dimensions are effectively prioritized. Therefore, cortex, striosomes, and dopamine work together to form a “decision-space”, only focusing on decision-dimensions that are necessary to solve the task at hand. In this light, sSPN and daSNC, via pairs of connected subpopulations that process information in parallel, serve the functional role of selecting precisely which decision-dimensions should receive high priority. In particular, dsSPNs select which direct pathway decision-dimensions to use, and isSPNs select which indirect pathway decision-dimensions to use (Fig. 2c, d, discussed in detail in Functional roles of dsSPNs, isSPNs, dmSPNs, and imSPNs). On the other hand, GPi, LHb, and RMTg, by prioritizing or deprioritizing all daSNC subpopulations together, determine precisely how many decision-dimensions should be used (Fig. 2e–g, Supplementary Fig. 2b–i).
Importantly, the advantage of this formation is not only conceptual, but practical for linking physiology to decision-making (Fig. 2h, Supplementary Fig. 2j–p). Distinct sSPN and/or daSNC subpopulations have been found to encode, for instance, reward12,14,15,35, cost12,14,15,35, or novelty48. Thus, we might imagine that decision-dimensions could correspond loosely to reward level, cost level, or novelty level. If this is the case, a logical prediction of the model arises: we would expect a low-dimensional decision-space to be formed during a simple choice (e.g. between two rewards) and a high-dimensional decision-space to be formed during a more difficult choice (e.g. between offers which each have benefits and costs that must be weighed in order to solve the problem). This hypothesis, if proven, would allow us to infer the decision-spaces of behaving rodents or humans simply by regressing sSPN activity on experimental parameters (for example, temperature or music volume), as we demonstrate using synthetic data (Supplementary Fig. 2q, r). For example, a significant correlation between sSPN activity and novelty level would indicate the existence of a decision-dimension that corresponds roughly to novelty (Inferring decision-space from SPN activity and choice, Methods). We sought to determine if this hypothesis is supported by experimental physiological data collected during decision-making.
Support for the model: context-dependent sSPN physiology matches model predictions
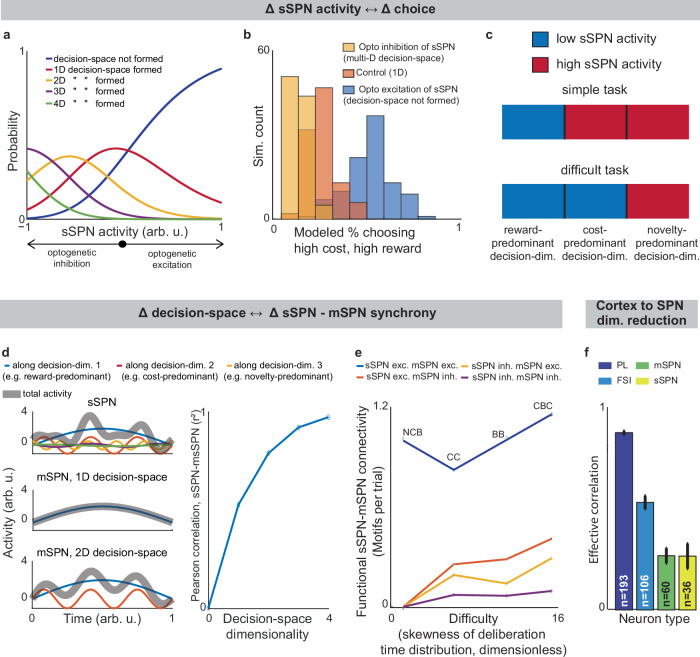
We began by asking whether the results of the physiological sSPN literature support a link between the decision-space (which our model postulates is driven by sSPN activity) and task difficulty (inferred from experimental inputs, for instance, a simple task with reward only versus a difficult task with conflicting rewards and costs). We began with the experimental literature on sSPNs. In one experiment11, sSPNs were optogenetically stimulated (or inhibited) during a rodent conflict decision-making task. Per our model, this should cause inhibition (or disinhibition) of daSNC neurons, leading to reduced (or enhanced) dopamine release to SPNs, producing a lower- (or higher-) dimensional decision-space. Indeed, the stimulation led to choices indicative of decision-making using few informational dimensions, while inhibition led to choices indicative of decision-making using multiple informational dimensions (Fig. 3a, b, Supplementary Fig. 3a, Effect of sSPN activity on decision-space and Effect of decision-space on choice, Methods). A second experiment11 tested, reversely, the activity of striosomes during simple versus difficult tasks. As the model expects, striosomal activity during simple tasks resembled the levels observed during optogenetic excitation, whereas striosomal activity during difficult tasks resembled the levels observed during optogenetic inhibition (Fig. 3c, Supplementary Fig. 3b–d). In another study, striosome activity was lower among rodents that learned a difficult reversal learning task than among rodents that did not10. Thus, there appears to be a relationship between sSPN physiology and task difficulty in the direction expected by our model.
Support for the model: context-dependent sSPN-mSPN synchrony matches model predictions
Importantly, the result above does not distinguish our model from the alternative, simpler explanation that sSPNs might collectively encode task difficulty. We could term such a model a “conflict model”, where sSPN activity tracks the overall conflict present in a task (see Supplementary Table 2). To determine whether it was changes to sSPN subpopulations driving the overall change in sSPN activity (i.e. decision-space), rather than a general effect, we analyzed the paired activities of sSPNs during simple versus difficult tasks using the Corticostriosomal Circuit Stress Experimental database3. We hypothesized that a greater number of sSPNs and mSPNs would be functionally connected during difficult tasks. This prediction arises from the circuit connectivity in our model, where sSPNs are functionally connected to mSPNs via daSNC, and each additional prioritized subpopulation causes more sSPN→daSNC→mSPN modulation (Fig. 3d). This could be observed, for instance, as an increase in striosome and matrix correlation as decision-space increases. This hypothesis is also inspired by the observation that striosome and matrix activity has been found to roughly track one another over time in a difficult task13.
To test this, we analyzed the synchrony between striosome neurons and matrix neurons during simple decisions (that forced choice between either two rewards or two costs) and during difficult decisions (that forced choice between offers that contained both rewards and costs together; see Supplementary Note 5). We measured synchrony as the cross-correlation between sSPN activity and mSPN activity over the period of the task. To control for possible physiological differences across the phases of the rats’ movements, we also developed a custom tool that uses Granger causality to measure how neurons interact over the span of the task (see Connected SPNs through Granger causality, Methods). Per both metrics, synchrony was significantly higher in the difficult task. Further, synchrony scaled with the difficulty with which the rats treated the difficult task, as measured based on deliberation time; that is, given different deliberation times for individual rats, given the same difficult decisions, longer deliberation times correlated with greater synchrony (Fig. 3e, Supplementary Fig. 3e–n, Connected SPNs through cross-correlation, Methods). Thus, rather than sSPNs encoding conflict in their general level of activity, there appears to be an important relationship between sSPN and mSPN subpopulations during high-conflict tasks. Our analysis does not confirm that sSPNs have a causal effect on mSPNs. However, if this is assumed, the evidence suggests enhanced modulation of mSPN subpopulations by sSPN subpopulations during the difficult tasks, that is, a formation of a higher-dimensional decision-space.
Support for the model: Dimensionality reduction from the cortex to SPNs
Notably, the synchrony analysis above demonstrates the use of subpopulations during context-dependent decision-making, but it does not test whether those subpopulations correspond to decision-dimensions. There is, however, evidence that SPNs encode what we term decision-dimensions. Experimental work has demonstrated that distinct SPN subpopulations encode different information, and that these subpopulations persist across days34. Further, our analysis suggests that dimensionality reduction occurs from the cortex to SPNs, as it does in our model during the mapping of information to a basis of decision-dimensions. Cortical neurons had the most coordinated activities over time (measured as effective correlation49), then FSIs, followed by sSPNs and mSPNs (Fig. 3f, Analyzing neural dimensionality reduction, Methods). This would suggest a higher-dimensional representation in cortex, where neurons encode similar information over time, than in the downstream regions, where information is compactly encoded in neurons that behave differently over time. Thus, it seems that cortex→SPN dimensionality reduction occurred during the tasks, like in our model the mapping from high-dimensional cortical information to a basis of SPN decision-dimensions.
Support for the model: Strong alignment to the experimental literature on SPNs compared to alternative models
Up until this point, the analysis is based on a selection of experimental literature relating sSPN activity to mSPN activity and choice. We wished to test the model more broadly using a range of experimental results. To this end, we devised five tests that link sSPN activity to choice, each verifiable with experimental literature, that might support or reject the decision-space model (Supplementary Fig. 3o–x, Supplementary Table 2). As benchmarks, we also constructed, from roles commonly assigned to sSPNs, four alternative models in which sSPNs only encode 1) conflict, 2) subjective value, 3) prediction error, or 4) actions. We found that while the alternative models each can be used to interpret a subset of the experimental evidence, only the decision-space model aligned to the breadth of it (Supplementary Table 3). A selection of experimental studies on GPi, LHb, and daSNC also align with the decision-space model (see Supplementary Tables 4–7), thus offering a new lens through which to interpret their functions.
Inability to form a high-dimensional decision-space in disorders
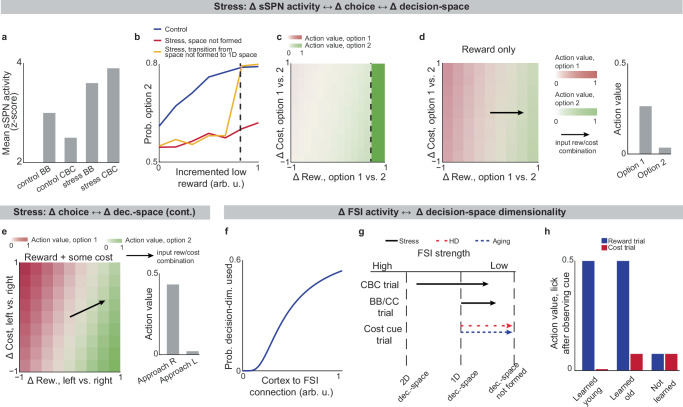
We next applied our model to the experimental literature on neuropsychiatric disorders, wondering if it could offer insight into disorders associated with sSPN changes. Interestingly, in an experimental study on chronic stress3, sSPNs were hyperactive compared to controls during the most difficult task but less affected during the simpler tasks (Fig. 4a). Meanwhile, the rodents were less adherent to reward level only in the difficult task, suggesting dysfunction in processing reward and cost together (Fig. 4b, c, Effect of decision-space on choice, Methods). Thus, we wondered if post-stress sSPN hyperactivity could cause altered choices due to a reduction in the dimensionality of the decision-space, similar to the model in Fig. 3b where optogenetic excitation reduced the decision-space in controls.
Our analysis supports this. Animals made decisions in the cost-benefit conflict task more quickly after stress, as if the task were less difficult (Supplementary Fig. 4a–d, Defining decision difficulty by task, Methods). Meanwhile, after stress, choices involving both reward and cost no longer had more functionally connected sSPNs and mSPNs than the simple tasks, suggesting a change to the decision-space as well as a general shift in activity. In fact, synchrony was similar across tasks and to the simple tasks for controls (Supplementary Fig. 4e–i). Thus, after stress, the rodents both showed both neural signatures aligned with a low-dimensional decision-space and choices aligned with processing of information in a low-dimensional way.
The inability to form a high-dimensional decision-space can also explain a counterintuitive finding that stress causes rodents to prefer a reward-cost combination over a reward presented without cost (Supplementary Fig. 4j, Changes to choice after adding cost to a reward offer, Methods). In classic economic theory, the addition of cost to a reward typically makes a commodity less attractive50 and thus our observation cannot be readily explained. In contrast, the decision-space model offers a simple explanation: cost can increase offer attractiveness in instances where cost level causes a transition from a default low-dimensional decision-space to a higher-dimensional decision-space, as we hypothesized is the case after stress in Fig. 4b, c. In these cases, the rules encoded by mSPNs can assign a higher value to accepting versus avoiding an offer when reward and cost are considered rather than only reward (Fig. 4d, e). In other cases, decisions are predicted to resemble those predicted by classic theory, for example in cases where either a one-dimensional (as in Fig. 4d) or two-dimensional (Fig. 4e) decision-space is used across cost levels.
Cortex→FSI connectivity is impacted by chronic stress3 (Supplementary Fig. 4k–r, Analyzed cortex-FSI connectivity and Modeled cortex-FSI connectivity after stress, Methods), leading to hyperactive sSPNs. Our model suggests that this causes the formation of a lower-dimensional decision-space (Fig. 4f, g), which would lead to lower variance and higher mean activity of SPN subpopulations (Supplementary Fig. 5). Notably, the cortex→FSI connection is also impacted in Huntington’s disease and aged rodents10, raising the possibility that an inability to form a high-dimensional decision-space during difficult decisions is a feature of multiple health conditions. Supporting this hypothesis, a model where Huntington’s disease and aged subjects use a lower-dimensional decision-space produces action values that follow the trend of experimental choice (Fig. 4h, Effect of decision-space on choice, Methods).
Interestingly, our model expects a low dimensional decision-space to be beneficial in disorder conditions. A feature of chronic stress3 and schizophrenia51 is reduced cortical signal-to-noise ratio (SNR) and disrupted cortical signaling. In these conditions, a low dimensional decision-space is theoretically optimal because only the highest-priority decision-dimensions carry enough signal to outweigh the drawback of noise (Supplementary Fig. 6, Effect of cortical SNR on choice, Methods). Our analysis raises the possibility that FSIs help steer the circuit towards a helpful decision-space in disorders.
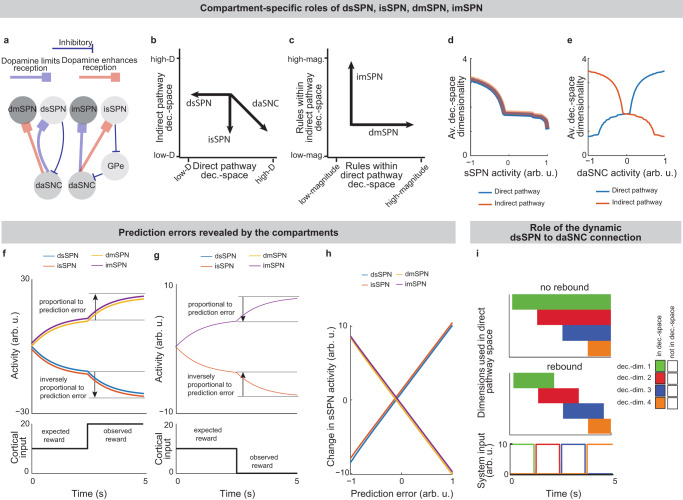
Functional roles of dsSPNs, isSPNs, dmSPNs, and imSPNs
sSPNs and mSPNs have been found to be distributed between the direct and indirect pathways of the striatum24,52,53, with dopamine release differently affecting sSPNs versus mSPNs and also dSPNs versus iSPNs20,40,54. Various neuropsychiatric disorders are associated with disturbed sSPN versus mSPN2 and direct versus indirect pathway balances33. Thus, the compartments likely play distinct functional roles in decision-making, including in disorders.
Because dsSPNs connect to dmSPNs through daSNC in our model, and isSPNs to imSPNs through GPe and daSNC, two decision-spaces are formed in parallel, one related to each pathway (Fig. 5a, Supplementary Note 6). Thus, based on the functional roles we assign to the pathways, the circuit uses a direct pathway decision-space to determine whether to perform an action and an indirect pathway decision-space to determine whether to refrain from it. dsSPNs influence the direct pathway decision-space while isSPNs influence the indirect pathway decision-space, and dmSPNs promote actions while imSPNs discourage actions (Fig. 5b–e, Modeling time-variant input, Methods). The circuit uses these compartment-specific mechanisms to calculate which actions should be performed with one set of decision-dimensions and calculate which actions should not be performed with another. The answers to these questions might overlap. For instance, the direct-pathway and indirect-pathway space should provide divergent answers to the value of consuming cocaine based on the dimensions they prioritized; the former, focusing on reward, might assign it great value while the latter, focusing on cost, might assign great value to not consuming it. When balances between the direct versus indirect pathways and striosome versus matrix changes, this calculus changes. For example, it has been found that dopamine release is enhanced to sSPNs versus mSPNs after cocaine administration55 and simultaneously dSPNs are enhanced in the short-term and iSPNs over longer-term scales of time56. This might lead to a high-dimensional direct-pathway decision-space but pruning of ordinarily important decision-dimensions from the indirect pathway decision-space, producing a reduction of nuance in determining when to avoid actions and heightened impulsivity.
Indeed, the model’s interpretation of the two parallel decision-spaces offers an intuitive explanation for a range of experimental observations on the direct versus indirect pathway. For example, our model replicates the experimental observations that increased dopamine leads to riskier and quicker decisions and preference for nearby offers, in time or physical proximity, compared to distant offers (Supplementary Fig. 7, Supplementary Table 7, Effect of dopamine on action/inaction values and Effect of decision-dimensions on choice, Methods).
Prediction error encoding is an emergent property of the model
A range of experimental studies have shown that SPN activities track prediction errors12,57. This observation has led to hypotheses that SPNs encode a function related to prediction errors in a reinforcement learning framework12. The decision-space model offers a different explanation. In our model, the weights from cortical neurons to SPNs naturally separate cortical information by their associations. For instance, if a bell tends to sound when a subject drinks chocolate milk, both stimuli, even if they arrive from different cortical sources, will likely be mapped to the same reward-related decision-dimension as synapses adjust per Oja’s rule. Less reliable cues are expected to develop mappings with smaller weights. Therefore, the activities of reward-related SPNs may rise when cues predicting rewards appear and fall when cues predicting less reward appear. A sudden change to reward information, for instance a predictive cue, should thus lead to a sudden change in the activity of an SPN subpopulation related to reward, and this change in activity should resemble a prediction error (Fig. 5f–h). Thus, in contrast with the more traditional interpretation where SPNs internally encode a temporal difference value function, the decision-space model suggests that the mapping of cortical activity to the basis of striatal decision-dimensions is sufficient to track prediction error in many cases, without additional computational work performed by the SPNs.
Both interpretations can be used to explain much of the experimental evidence, although the interpretation of the decision-space model may more closely align to recent experimental data (Supplementary Tables 2, 3). Our model also may provide a functional rational for the observation that separate SPNs encode data along different informational axes12,14. In fact, our model expects more of these axes to be uncovered by future work. We might expect, for instance, a cue predictive of the novelty of an object to produce an immediate change in activity of an SPN subpopulation related to novelty.
How might the circuit respond in cases where new information diverges sharply from expectations? Our model predicts that in these cases, sSPNs will signal to daSNC that a decision-dimension should be reprioritized, effectively adding or removing the dimension from the decision-space. Interestingly, the circuit has an inherent physiological mechanism to quickly transition away from a decision-space that is no longer optimal. Experimental evidence has identified rebounds in daSNC activity21 and striatal dopamine release18 after sSPN optogenetic stimulation. Our model suggests that these observations are part of a system by which the circuit can rapidly de-prioritize a decision-dimension after a negative prediction error (e.g. less reward than expected). Thus, the circuit is able to quickly shift to a more helpful decision-space (Fig. 5i). During learning, these shifts between decision-spaces will occur when the subject is surprised to encounter a decision-dimension that does not align with their experience. For instance, during a reinforcement learning T-maze task, the decision-space will shift when the two options are suddenly reversed (Supplementary Fig. 7j–l). These shifts occur during the trials where there are the largest RPE. So, shifts in the decision-space might not only align with RPEs in magnitude, but might be coordinated with RPEs over time.
Discussion
We found evidence, through experimental literature and our analysis of neural recordings, to support our hypothesis that modeled physiological patterns in SPN activity (the decision-space) can be used to predict patterns in decision-making, and vice versa. This supports our model of the roles of striosomes and matrix neurons of the direct and indirect pathways in context-dependent decision-making.
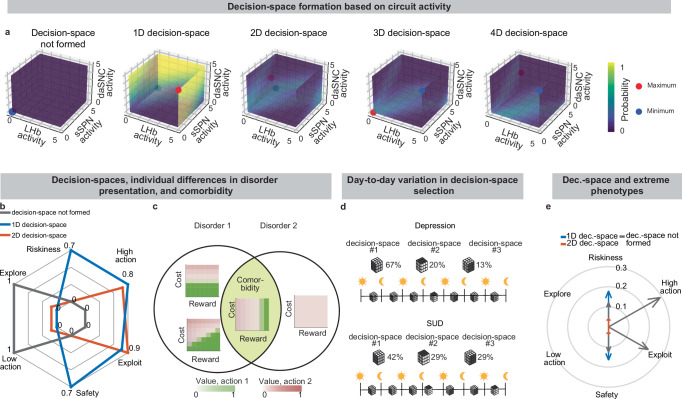
Due to the circuit’s important role in decision-making processes, including in neuropsychiatric disorders, our model provides a framework with which to study decision-making phenomena commonly observed in psychiatry. An important prediction of our model is variance in context-dependent decisions, between individuals and over time (Fig. 6a–d, Supplementary Fig. 8a–e, Effects of sSPN, LHb, and daSNC activity on choice profiles, Methods). Individual differences in decision-making as a function of disorders, as seen in the experimental literature58–60, could arise in cases where there are slight differences in activity of the circuit we model, leading to similar decision-making phenotypes only when a similar decision-space is formed. Daily variance in decision-making, a common observation in pscyhology61, could arise from daily variance in circuit activity, causing day-to-day variability in the decision-spaces formed most often. Further, differences in circuit activity may explain the established inter-individual differences in the severity of psychiatric disorder symptoms observed during decision-making62,63. Individual differences in disorder susceptibility could arise from reliance upon or avoidance of a decision-space that leads to extreme decision-making tendencies (e.g. extremely action-heavy, extremely risk-averse) when combined with abnormal action value rules in mSPNs (Fig. 6e and Supplementary Fig. 8f).
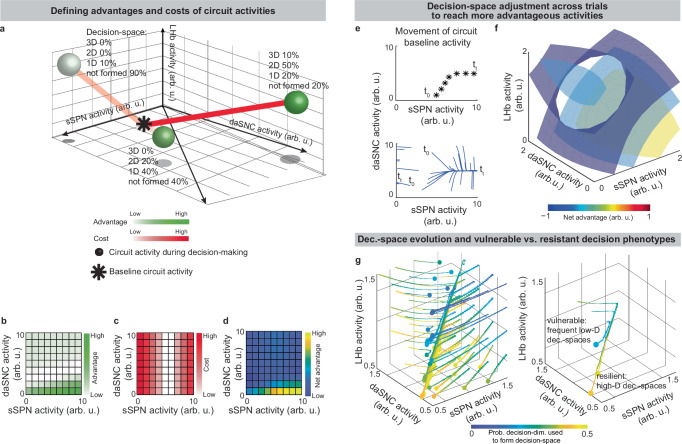
Our model serves as a framework for forming hypotheses about changes to the circuit across days and weeks, including during neuropsychiatric disorder progression. Our model expects the circuit to adapt between trials as it adjusts to more frequently form a preferred decision-space (Fig. 7a–f, Effect of initial circuit activity on future trials, Methods). So, vulnerability or resilience to disorders can be framed as an adaptation that is favorable (e.g., to adeptly form a high-dimensional decision-space) or maladaptive (e.g., to only form a low-dimensional decision-space, regardless of decision context). Depending on its initial activity, a modeled circuit can adapt to reach very different activity, leading to disposition to either a high- or low-dimensional decision-space (Fig. 7g and Supplementary Fig. 9a). Thus, differences in the circuit before exposure to a traumatic event, for instance, may explain why two subjects that encounter the same traumatic event do not always develop the aberrant decision-making symptoms of post-traumatic stress disorder (PTSD)64. It may also shed light on the neural processes underlying incubation of fear65 and incubation of craving66, where disorders progress over the span of weeks or months, even when the traumatic event or addictive substance does not reappear (Supplementary Fig. 9b–d, Effect of altered advantage score on future trials, Methods). By representing the role of SPNs in a compartment-specific way, our model facilitates understanding of disorders that affect striosomes and matrix differentially.
Our model carries several limitations, including its limited focus on a dorsomedial striosomal circuit and certain physiological assumptions (Supplementary Notes 1–4). We limit our focus to a specific circuit that has been implicated in decision-making, rather than attempting a unifying theory of basal ganglia function or decision-making encoding across the brain (Supplementary Note 2). While we demonstrate alignment to the existing experimental evidence in Figs. 2 and 3 and Supplementary Tables 2–7, future experiments (outlined in Supplementary Fig. 10) will be required to confirm the assumptions we make. Despite these limitations, our model has demonstrated success in relating neural activity to decision-making across a range of behavioral tasks and has the power to explain a range of phenomena, from neural processes to psychiatric observations. Additionally, we expect it to serve as a foundation for future work on other brain regions like substantia nigra and other pathways such as are formed by arkypallidal neurons of the GPe (Supplementary Note 7). Finally, it adds precision to other models (Supplementary Note 8), including reinforcement learning models of the basal ganglia (Supplementary Note 9).
Methods
Outline
- Decision-dimensions and decision-space. Explanation of the foundational concept of the model.
- Analyzed instances of the model. We conduct our analysis using three instances of the conceptual model. In the following sections, we formally define the model in each instance, then detail the methods behind our related analyses.
- Shifts in the decision-space in a reinforcement learning task. Reinforcement learning simulations to analyze the differences between the decision-space model and the classical reinforcement learning model of the basal ganglia. Related to Supplementary Fig. 6j–l.
- Movement of circuit activity across multiple trials. An extension of the model to view possible changes of the circuit between trials in the context of decision-space. Related to Fig. 7, Supplementary Fig. 9.
- Reasoning behind the FSI model. Mathematical choices made in the model of fast-spiking interneurons (FSIs).
- Inferring decision-space from SPN activity and choice. A method we designed in which decision-space can be inferred from experimental data. Related to Supplementary Fig. 2q, r.
- Testing the model through analysis of neural data. Analysis of neural data which supports our model. Related to Fig. 3e, f, Supplementary Figs. 3a–n, 4a–p.
Decision-dimensions and decision-space
The physiologies of the circuit elements produce two abstractions which we use, for convenience, throughout our work:
- A decision-dimension is an axis of the coordinate system with which SPNs (dsSPNs, isSPNs, dmSPNs, imSPNs; see Table 1 for anatomical definitions) encode data projected from the cortex. A decision-dimension is equivalent to a principal component of cortical activity. In our analysis, separate groups of SPNs encode data along the first, second, third, and fourth principal components. (Arbitrarily, we do not consider principal components beyond the first four). Each of the dsSPN/isSPN/dmSPN/imSPN subgroups have neurons corresponding to each of the four principal components.
- The decision-space is the mathematical space formed by mSPNs (both dmSPNs and imSPNs) after dopamine signaling from daSNC. Modeled dopamine signaling determines whether to include or exclude neurons encoding each decision-dimension during a decision. Thus, from the mathematical space formed by all decision-dimensions, a mathematical subspace (i.e. the “decision-space”) is formed with which to define action values.
We use the prefix “decision” because the circuit uses decision-space, formed from a basis of decision-dimensions, to define action values during decision-making.
In our analysis, we give “reward,” “cost”, “novelty”, and “location” as examples of informational axes that might roughly correspond to decision-dimensions. These examples follow from the intuition that: 1) these axes seem to be roughly orthogonal, as are decision-dimensions; 2) these axes are continuous, making representation in decision-dimensions intuitive. Additionally, the experimental evidence suggests that some striosomes or daSNC selectively encode reward12,14,15,35, cost12,14,15,35, or novelty48. Finally, a location-predominant decision-dimension could explain the experimental observations modeled in Supplementary Fig. 7i.
In reality, we would not expect any informational axes to align perfectly with any decision-dimension, although some axes should logically align with certain decision-dimensions better than others. (For instance, there must exist a decision-dimension that aligns with reward level the most out of any decision-dimension.) Also, note that while we refer to, for instance, a “reward-predominant” decision-dimension, this does not mean that it is expected to track only reward. Instead, many other axes of data might roughly align with it, including reward level. For example, a decision-dimension that roughly corresponds to reward might also be found to track information about the color green, or the pleasantness of a smell, or the sound of a bell. We can imagine that a variety of other information might also map to decision-dimensions. For example, information about social dominance, the desire to replicate, exploration, and morality might be found along different decision-dimensions.
In our equations (e.g. eq. 2), we use the index i to refer to the sSPN, daSNC, or mSPN population corresponding to a certain decision-dimension (out of q total decision-dimensions in each of the direct and indirect pathways). Meanwhile, we use the index j to refer to a certain action (out of k total actions).
Analyzed instances of the model
The general case of the model (although not formally used for analysis) is a dynamic network of cortical neurons, FSIs, dsSPNs, isSPNs, GPi, LHb, daSNCs, dmSPNs, imSPNs, and mSPN-projecting neurons which encode action values.
We conduct our analyses using three instances of this general case, which are each equivalent to the general case under the specific conditions we outline. The three instances, tailored to our various analyses, each allow for a different mathematical simplification. This allows us to conceptually and formally define the instances individually in a way that is intuitive and relates directly to our analyses.
- Instance 1 has full cortex→FSI → SPN connectivity and constant activity in each circuit element throughout the decision. In this instance, the model can be defined equivalently using a smaller set of network elements and a feedforward network. See Instance 1: full connectivity and feedforward.
- Instance 2 has constant activity in each circuit element throughout the decision. In this instance, the model can be defined equivalently using a feedforward network. See Instance 2: sparse connectivity and feedforward.
- Instance 3 has full cortex→FSI → SPN connectivity. In this instance, the model can be defined equivalently using a smaller set of network elements. See Instance 3: full connectivity and dynamics.
Instance 1: full connectivity and feedforward
In this section, we describe the instance of the model where each cortical neuron projects to each FSI, each FSI projects to each SPN (for dsSPN, isSPN, dmSPN, imSPN), and each cortical neuron projects to each SPN. Additionally, cortical input to the system does not change over time, and the activities of other circuit elements do not decay over time.
This instance of the model leads to a convenient formation of the model as a circuit of fewer elements (one FSI, one dsSPN, isSPN, dmSPN, and imSPN per the four decision-dimensions), and no time component. In this section, we frame this instance mathematically and then describe our related analysis. See Fig. 1c for a circuit diagram.
Input: cortical activity
During a decision, a vector of cortical input \({{{{\bf{x}}}}}_{P}\in {{\mathbb{R}}}^{p\times 1}\) enters each pathway P in the network (xdirect to direct pathway SPNs and xindirect to indirect pathway SPNs). The elements of xP are the activities of p cortical neurons. Each neuron encodes a different sensory input.
Outputs
We use this instance of the model to examine: 1) the activities of the circuit elements depending on the activities of other circuit elements (Fig. 2, Supplementary Fig. 2a–i); 2) the modulation of mSPNs by dopamine (i.e. decision-space, Fig. 2a, b); 3) action values given decision-space (Supplementary Fig. 2j–l), and 4) choice given action values (Supplementary Fig. 2m–p).
- The activities of circuit elements during a decision are related to each other based on anatomically realistic connections (eqs. 1–3, 5, 7).
- A decision-space is formed probabilistically. The probability of a given decision-dimension i being used during a decision is equivalent to the activity of daSNC (see eq. 2), which ranges from 0 to 1. Probabilities are realized in the connection from daSNC to mSPN (see eq. 3), when each decision-dimension is probabilistically assigned a weight (in most analyses, either 0 or 1). Decision-space is defined as the space formed from the basis of decision-dimensions that were not assigned a weight of 0.
- Action value is derived based on mSPN activity during a decision.
- Choice is derived from action values. Action values are treated as Merton processes44 using eq. 12. Several possible actions are assigned action values and the corresponding process that hits the threshold first is enacted.
Defining FSI activity
FSI activity, cP, is set to the magnitude of xP for each pathway, multiplied by a weight of cortex→FSI connection aFSI, plus an additive shift bFSI:
\[
{c}_{P}={a}_{FSI}\cdot ||{{{{\bf{x}}}}}_{P}||+{b}_{FSI}
\]
where:
- cP is relative activities of FSIs that project to SPNs of pathway P (activity arb. u.)
- aFSI is the weight of cortex→FSI connection. Similar for both P. (dimensionless)
- xP is the activities of cortical neurons that project to SPNs of pathway P. (activity arb. u.)
- bFSI affects the relative activity of all sSPN neurons. Similar for both P. (activity arb. u.)
In the current instance of the model, there are 2 FSIs, one that receives input from xdirect and projects to dsSPNs and dmSPNs, and the other that receives input from xindirect and projects to isSPNs and imSPNs.
For use in our analysis, see https://github.com/dirkbeck/DM_space_model/blob/main/algorithmic_model.m.
Defining sSPN activity
To get the activities of sSPNs in each pathway, xP is normalized via division by cP and multiplied by \({{{{\bf{W}}}}}_{{P}}\in {{\mathbb{R}}}^{{p}\times q}\), which linearly transforms and reduces cortical input from the p-dimensional coordinate space of cortex to the smaller q-dimensional coordinate space of sSPN. In the sSPN coordinate space, each coordinate is a principal component of a training set of historical cortical input across n time steps \({{{{\bf{X}}}}}_{P}\in {{\mathbb{R}}}^{n\times p}\) (uncorrelated, for simplicity). For each pathway, WP contains the truncated first q columns (corresponding to the first q principal components) of \({{{{\bf{W}}}}}_{{{{\rm{full}}}},P}\in {{\mathbb{R}}}^{p\times p}\) after the decomposition \({{{{\bf{X}}}}}_{P}{{{{\bf{X}}}}}_{P}^{{{{\rm{T}}}}}={{{{\bf{W}}}}}_{{{{\rm{full}}}},P}{{{\mathbf{\Lambda }}}}{{{{\bf{W}}}}}_{{{{\rm{full}}}},P}^{{{{\rm{T}}}}}\) is made to obtain the full principal component matrix. There is dimensionality reduction on the order of ~100 times from cortex to SPNs (Supplementary Note 3), so \(q\ll p\). Note that in our analysis using the current instance of our model, XP is not explicitly generated because we specify the inputs to the system in terms of the coordinate space of decision-dimensions.
For each pathway, the components of an sSPN activity vector \({{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}\in {{\mathbb{R}}}^{q\times 1}\) each correspond to the activity of an sSPN circuit element. A constant bsSPN, used in analyses where modeled sSPN activity is stimulated or inhibited, adjusts overall sSPN activity:
\[
{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}=\frac{1}{{c}_{P}}{{{{\bf{W}}}}}_{P}^{{{{\bf{T}}}}}{{{{\bf{x}}}}}_{P}+{b}_{{{{\rm{sSPN}}}}}
\]
where:
- cP is the relative activity of the FSI projecting to SPNs of pathway P (activity arb. u.)
- WP is a matrix of weights from cortical neurons to SPNs of pathway P. Each column is equivalent to a principal component of cortical activity. (dimensionless)
- xP is the activities of cortical neurons that project to SPNs of pathway P. (activity arb. u.)
- bsSPN affects the relative activity of all sSPN neurons (activity arb. u.)
In the current instance of the model, activities are defined based on a feedforward network, so the simplification is made that sSPN activities are not affected by daSNC activities.
In the current instance, there is one sSPN per decision-dimension per pathway. So, there are q dsSPNs and q isSPNs. The dsSPNs receive input from xdirect and cdirect. The isSPNs receive input from xindirect and cindirect.
For use in our analysis, see https://github.com/dirkbeck/DM_space_model/blob/main/algorithmic_model.m.
Defining GPi, LHb, and RMTg activities
The GPi→LHb→RMTg→daSNC pathway performs a series of operations which influence RMTg activity RMTg, which is an input to daSNC activity in eq. 2. Weights \({{\mathbf{w}}}_{{{\mathbf{GPi}}},{P}} \in {\mathbb{R}}^{2q\times1}\), not necessarily positive, are combined with the activities of the q dsSPNs and q isSPNs, forming scalar representations of dsSPN or isSPN activity. \({z}_{{{{\rm{GPi}}}}}\), \({z}_{{{{\rm{LHb}}}}}\), and \({z}_{{{{\rm{RMTg}}}}}\) terms reflecting the activities of those circuit elements are combined with this scalar representation:
\[
{{\mathrm{RMTg}}}={z_{{\mathrm{RMTg}}}}+{z_{{\mathrm{LHb}}}}+{z_{{\mathrm{GPi}}}}\; \cdot\; {{\mathbf{w}}}_{{\mathbf{GPi}}}\;\cdot\;\left[{{{{\mathbf{s}}}_{{{\mathbf{sSPN}}},{{\mathrm{direct}}}}}\hfill \atop{{{\mathbf{s}}}_{{{\mathbf{sSPN}}},{{{\mathrm{indirect}}}}}}}\right]
\]
where:
- \({z}_{{{{\rm{RMTg}}}}}\) is an additive shift that affects relative RMTg activity (activity arb. u.)
- \({z}_{{{{\rm{LHb}}}}}\) is an additive shift that affects relative LHb activity (activity arb. u.)
- \({z}_{{{{\rm{GPi}}}}}\) is a coefficient that affects relative GPi activity (activity arb. u.)
- wGPi is the weights of connection from sSPNs of pathway P to the GPi neuron (dimensionless)
- ssSPN,P is the activity of sSPNs corresponding to decision-dimension i and pathway P (activity arb. u.)
This pathway contains one GPi element, one LHb element, and one RMTg element, as visualized in Fig. 1c. All sSPN elements project to GPi. GPi activity is an input to LHb, which after the \({z}_{{{{\rm{LHb}}}}}\) addition, is an input to RMTg, which itself has a \({z}_{{{{\rm{RMTg}}}}}\) addition. For simplicity, these series of operations are presented together in eq. 7.
For use in our analysis, see https://github.com/dirkbeck/DM_space_model/blob/main/algorithmic_model.m.
Defining daSNC activity
daSNC neurons incorporate the output of the GPi→LHb→RMTg→daSNC pathway with direct inputs from sSPN elements. There are q sSPN elements of each pathway and q daSNC elements corresponding to each pathway. For each pathway, the ith sSPN element connects to the ith daSNC element, but not to other daSNC elements (see Fig. 1c). These connections have weights \({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}\) for i = 1, 2, …, q. RMTg, on the other hand, connects to each daSNC element. Only for the indirect pathway, sSPNs connect to daSNC through GPe. (That is, \({z}_{{{{\rm{GPe}}}},{{{\rm{direct}}}}}=0\)). The output of the ith daSNC element, constrained to between 0 and 1 via a logistic function, captures the importance of a single decision-dimension:
\[
{{{{\rm{daSNC}}}}}_{i,P}=\frac{1}{1+\exp ({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}\cdot ({{{{s}}}}_{{{{\rm{s}}}}{{{\rm{S}}}}{{{\rm{P}}}}{{{\rm{N}}}},i,P}+{z}_{{{{\rm{GPe}}}},P})+{{{\rm{RMTg}}}}-{z}_{{{{\rm{daSNC}}}},i,P})}
\]
where:
- \({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}\) is the weight of connection from the sSPN corresponding to decision-dimension i and pathway P to the daSNC corresponding to decision-dimension i and pathway P. The weight is fixed in this instance of the model. (dimensionless)
- ssSPN,i,P is the activity of sSPNs corresponding to decision-dimension i and pathway P (activity arb. u.)
- \({z}_{{{{\rm{GPe}}}},P}\) is the activity of GPe (activity arb. u.)
- \({z}_{{{{\rm{daSNC}}}},i,P}\) is an additive shift applied to the daSNC neuron corresponding to decision-dimension i and pathway P (activity arb. u.)
- RMTg is RMTg activity, as defined in eq. 7. (activity arb. u.)
This pathway is modeled using one neuron per decision-dimension per pathway. So, there are q daSNC neurons that each receive projection from a dsSPN, and q daSNC neurons that each receive projection from an isSPN. daSNC elements also receive input from RMTg.
For use in our analysis, see https://github.com/dirkbeck/DM_space_model/blob/main/algorithmic_model.m.
Defining mSPN activity and the decision-space
In each pathway, the decision-space is formed probabilistically. The conversion from daSNC activity to realization of the decision-space occurs in the connections from daSNC to mSPN. There are q daSNC elements corresponding to each pathway and q mSPN elements, and, in each pathway, the ith daSNC element connects to the ith mSPN element, but not to other mSPN elements (see Fig. 1c).
Like sSPNs, mSPNs encodes the cortical input normalized by an FSI and is transformed to a coordinate space of the first q principal components. The difference is that for each of dmSPNs and imSPNs, a diagonal matrix \({{{{\bf{S}}}}}_{P}\in {{\mathbb{R}}}^{q\times q}\) is multiplied by the cortical input after transformation:
\[
\begin{array}{c}{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}=\frac{1}{{c}_{P}}\end{array}{{{{\bf{S}}}}}_{P}{{{{{\bf{W}}}}}_{P}}^{{{{\bf{T}}}}}{{{{\bf{x}}}}}_{P}
\]
where:
- cp is the relative activity of the FSI projecting to SPNs of pathway P (activity arb. u.)
- SP is a diagonal matrix that applies dopamine release (via daSNC activity) to mSPN activity in pathway P. (dimensionless)
- WP is a matrix of weights from cortical neurons to SPNs of pathway P. Each column is equivalent to a principal component of cortical activity. (dimensionless)
- xP is the activities of cortical neurons that project to SPNs of pathway P. (activity arb. u.)
In the current instance, there is one mSPN per decision-dimension per pathway. So, there are q dmSPNs and q imSPNs. The dmSPNs receive input from xdirect and cdirect. The imSPNs receive input from xindirect and cindirect.
The diagonal elements of SP are set probabilistically to either 1 (dimension in decision-space) or 0 (dimension not in decision-space) such that \({{\mathrm{P}}}\bigl({{\mathbf{S}}}_{P,{{\mathrm{ii}}}}=1\bigr) \;=\; {{\mathrm{daSNC}}}_{i,P}\).
Thus, in the portions of our analysis where we set the activities of the q daSNC elements to be equal, the decision-dimensions each have the same probability of being included in decision-space, i.e. \({{{{\rm{daSNC}}}}}_{1}={{{{\rm{daSNC}}}}}_{2}={{\mathrm{..}}}.={{{{\rm{daSPN}}}}}_{q}=d\). In this case, we treat the probability of a certain decision-space dimensionality forming as a binomial distribution:
\[
{{\mathrm{P}}}\bigl(m\,{{\mbox{ decision}}}{\mbox{-}}{{\mbox{dimensions}}} \,{{\mbox{used}}} \,{{\mbox{to}}} \,{{\mbox{form}}} \,{{\mbox{decision}}}{\mbox{-}}{{\mbox{space}}}\bigr)=\left({{q}\atop{m}}\right)\,d^{m}\,(1-d)^{q-m}\quad {{\mbox{for }}}\,m=0,1,\ldots,{{\rm{q}}}.
\]
where:
- q is the number of possible decision-dimensions
- d is the (equal) probability that each decision-dimension is used to form decision-space
Defining action value
Action value (or, in the indirect pathway, inaction value) vj,P for each of k potential actions is defined based on the activities of dmSPNs (or imSPNs). During this process, elements of a coefficient matrix \({{\mathbf{\beta}}}_{P} \;\in\; \mathbb{R}^{k \times q}\) are applied to mSPN activities for each decision-dimension, action, and pathway. Bias αj,P is subtracted. Below, βj,P is used to indicate row j of βP.
\[
{v}_{j,P}=\frac{1}{1+\exp (-{{{{\mathbf{\beta }}}}}_{j,P}\,{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},P}-{\alpha }_{j,P})},
\]
where:
- βj,P is a matrix of weights from dmSPNs to downstream action value encoding neurons for the direct pathway, or imSPNs to downstream inaction value encoding neurons for the indirect pathway. (dimensionless)
- smSPN,P is the activity of sSPNs corresponding to decision-dimension i and pathway P (activity arb. u.)
- αj,P is an additive shift corresponding to the neuron encoding action j for the direct pathway or inaction j for the indirect pathway. (activity arb. u.)
There is one neuron encoding each vj,P. So, there are k neurons encoding action values and k neurons encoding inaction values. Each of these neurons receives projections from all mSPNs of the corresponding pathway.
Defining choice
k Merton processes44 are run to determine whether each action should be taken, and another k to determine whether each action should be refrained from. Progress to choice for each action (or inaction), Yj,P, is related to its corresponding action (or inaction) value vj,P and an uncorrelated Brownian component dWj,P scaled by a coefficient σ.
\[
{{\mathrm{d}}}Y_{j,P}=v_{j,P}\,{{\mathrm{d}}}t+\sigma\,{{\mathrm{d}}}W_{j,P}, Y_{j,P}(0)=0,\quad{{\mbox{where }}}\;W_{j,P}\;{{\mbox{ is}}}\; {{\mbox{a}}}\; {{\mbox{standard}}}\; {{\mbox{Wiener}}}\; {{\mbox{process.}}}
\]
where:
- Yj,P is the progress to enaction of action j in the direct pathway, and progress to refraining from action j in the indirect pathway.
- vj,P is the action (or inaction) value corresponding to action j and pathway P. (activity arb. u.)
- σ is the coefficient of noise.
The time it would take to enact action j, \({t}_{{{{\rm{action}}}},j}\), is defined as the first hit time of a threshold h for process j of the direct pathway:
\[
t_{{{\mathrm{action}}},j}={\min}_{t}\bigl\{\,t \mid Y_{j,{\mathrm{direct}}}\ge h\bigr\}
\]
The time it takes to exclude action j from consideration, \({t}_{{{{\rm{inaction}}}},j}\), is calculated similarly using the indirect pathway:
\[
t_{{{\mathrm{inaction}}},j}=\mathop{\min}_{t}\bigl\{\,t \mid Y_{j,{\mathrm{indirect}}}\ge h\bigr\}
\]
The enacted action is the first to reach \(h\), given that the corresponding inaction process has not first reached \(h\):
\[
{{{\rm{action}}}}={\mbox{arg}}\,{\min }_{j\in J}({Y}_{j}({t}_{{{{\rm{action}}}},j})),\,{{{\rm{where}}}}\,J\,{{{\rm{is}}}}\,{{{\rm{the}}}}\,{{{\rm{subset}}}}\,{{{\rm{of}}}}\,{{{\rm{actions}}}}\,{{{\rm{s}}}}{{{\rm{.t}}}}.\,{t}_{{{{\rm{action}}}},j} < {t}_{{{{\rm{inaction}}}},j}
\]
where:
- Yj,P is the progress to enaction of action j in the direct pathway, and progress to refraining from action j in the indirect pathway.
- t is time (s)
- h is a threshold at which an action is considered taken (progress to decision arb. u.)
In our analysis, we run simulations using a constant time step discretization of eq. 12.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/weiner_process_model.m.
Modeled circuit manipulation using Instance 1
To get a sense of the functional role of the circuit elements, we conducted sensitivity analyses by changing parameters in the model individually and determining their effect on the activities of other circuit elements, the decision-space and/or choice.
Common parameters
The values specified here, arbitrarily chosen, are used in the analyses in Instance 1 unless otherwise indicated:
- throughout, k = 4
- in eq. 1: bsSPN = 0
- in eq. 2: \({w}_{{{\rm{sSPN}}}\to {{\rm{daSNC}}},i,P}=1\) for all i and P
- in eq. 2: \({z}_{{{\rm{daSNC}}},i,P}=1\) for all i and P
- in eq. 4:, \({{{\mathbf{\beta }}}}_{{{\rm{direct}}}}=\left(\begin{array}{cccc}1 & -1 & 0 & 0\\ -1 & 1 & 0 & 0\\ 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0\end{array}\right)\)
- in eq. 4: αj,P = −3 for all j and P
- in eq. 5: aFSI = 1
- in eq. 5: bFSI = 0.5
- in eq. 7: \({z}_{{{\rm{LHb}}}}=0.5\)
- in eq. 7: \({z}_{{{\rm{RMTg}}}}=0.5\)
- in eq. 7: \({z}_{{{\rm{GPi}}}}=1\)
- in the inputs to eq. 10, q = 4
- in eq. 12: σ = 1
- in eq. 13, 14: h = 2
whose rows correspond to, for example: turning left, turning right, turning around, wandering; and whose columns correspond to, for example: a reward-predominant decision-dimension 1, a cost-predominant decision-dimension 2, a novelty-predominant decision-dimension 3, and a location-predominant decision-dimension 4. The coefficients model a T-maze where a choice is made to turn right or left based on relative values of cost and reward.
Rationale behind parameter choices
The parameters chosen above are set to these default values in order to probe the selective effects of different circuit elements on the decision-space, action values, and choice, whose units are often arbitrary. Thus, we make our parameter choices arbitrarily, but with an emphasis on computational simplicity.
We can think of the free parameters as falling into three groups. This is because the circuit operates in a three-step process: first the decision-space is formed, then action values are defined, then choices are made by downstream neural circuits. So, parameter choices in a Group 1 affect the decision-space, parameter choices in a Group 2 affect action values, and parameter choices in a Group 3 affect choice. More precisely,
- Group 1 affects the decision-space, and action values and choice only via the decision-space. The parameters in eqs. 1, 2, 5, 7, fall in Group 1.
- Group 2 affects action values and choice via action values but not the decision-space. The parameters in eq. 4 fall in Group 2.
- Group 3 affects choice, but not action values nor the decision-space. The parameters in eqs. 12, 13, and 14 fall in Group 3.
We chose the common free parameters in Group 1 with the goal in mind of probing the relative effects of circuit elements on the decision-space. That is, we use the model to gain intuition about how each circuit element will affect daSNC activity, given their physiological relationships. For instance, \({z}_{{{{\rm{LHb}}}}}\) and \({z}_{{{{\rm{RMTg}}}}}\) in eq. 7 are mathematically redundant, but are included because the effect of the brain regions individually is important to our analysis (see Supplementary Table 5). In all cases in our fitting to data involving Group 1 free parameters, we analyze relative rather than absolute effects of changes to neural activity. For instance, we examine differences between high versus medium versus low striosome activity in Figs. 3 and 4 and Supplementary Table 3. Note that the activities are given in arbitrary units, so other combinations of parameter values with the same net effect would reproduce our results exactly (for instance, \({z}_{{{{\rm{LHb}}}}}=1\), \({z}_{{{{\rm{RMTg}}}}}=0\)). The current choices of common parameters were arbitrary, but selected so that the eq. 2 simplifies to a logistic function with a bias term \(f(x)=\frac{1}{1+{{{{\rm{e}}}}}^{x+b}}\) when the activities of all circuit elements are set to their defaults. So, absent any change to the defaults among the circuit elements, and absent any inputs from cortex above or below baseline, each decision-dimension has 50% probability of being used to form the decision-space.
In Group 2, βdirect and αj,P are constructed as an example of a scenario often used during our analysis, where there are two decision-dimensions that convey opposite information (e.g., the first reward-predominant, the second cost-predominant) that affect whether to take two actions (e.g. turning right or left). Thus, the signs of the numbers in βdirect are modeled from the task, but it could be scaled by any coefficient greater than 0 and achieve similar results to our analysis. We chose a negative value for αj,P to reflect its functional role as a prior. So, a given action is assigned low value unless there is significant evidence that it is valuable. αj,P is assigned arbitrarily, although very low αj,P would lead to action values near 0 and very high αj,P would lead to action values near 1.
In Group 3, we chose parameters that roughly reproduced experimental deliberation time distributions (see Supplementary Fig. 3b, c).
Effect of reward/costs on LHb/RMTg/daSNC activity
In Supplementary Fig. 2e, f, we modeled the effect of incrementing reward or cost on the activities of LHb, RMTg, and daSNC.
The inputs enter the model circuit in two ways: 1) reward and cost are mapped to decision-dimensions; and 2) cost level leads to changes in LHb and RMTg activities, similar to what has been demonstrated in the experimental literature (described in Supplementary Note 12). The modeled LHb and RMTg responses to cost are proportional to cost level with an arbitrary coefficient (set to 1 for LHb and 0.9 for RMTg for the purposes of plotting).
The modeled results show that the mean activity of a daSNC subpopulation encoding reward-predominant data responds positively to increases in reward and negatively to decreases in reward, similar to what has been demonstrated in the experimental literature (described in Supplementary Note 12). LHb and RMTg respond negatively linearly to reward level and positive linearly to cost level, similar to trends in the experimental evidence (see Supplementary Information). Sudden changes in reward or cost level, therefore, lead to shifts in activities that track changes to expectations of future reward or cost value, including reward or cost currently received, i.e. reward or cost prediction error.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_overview/GPi_LHb_RMTg_DA_model.m.
Effect of LHb/RMTg/daSNC activity on the decision-space
In Supplementary Fig. 2g-i, we modeled the effect of incrementing GPi, LHb, RMTg, or daSNC activity on the type of decision-space formed during a decision.
In the plotted analysis, we altered \({z}_{{{{\rm{GPi}}}}}\) in eq. 7, \({z}_{{{{\rm{LHb}}}}}\) in eq. 7, \({z}_{{{{\rm{RMTg}}}}}\) in eq. 7, and \({z}_{{{{\rm{daSNC}}}},i,P}\) (uniform change for all i, a single pathway is considered) in eq. 7 such that they took 10 values incremented from 0 to 1. Parameters not altered took default values (see Common parameters).
We also examined the role of each component in decision-space formation through the perspective of a series of steps, each carried out by a different circuit element. For this analysis, we substituted eq. 7 into eq. 2 and altered each parameter in turn. The plots illustrate the value of daSNCi,P if the other parameters were set to 1 (\({z}_{{{{\rm{GPi}}}}}\)) or 0 (\({z}_{{{{\rm{RMTg}}}}}\), \({z}_{{{{\rm{daSNC}}}},i,P}\)). bLHb is set to 0.5 (control), −5 (lesioned LHb), or 5 (stimulated LHb).
See Supplementary Tables 5,6 for alignment to the experimental literature.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_overview/GPi_LHb_RMTg_DA_model.m.
Effect of sSPN and mSPN activity on the decision-space and action values
In the analysis plotted in Fig. 2c, we incremented bsSPN in eq. 1 from 0 to 1 arbitrary units and recorded the value of daSNCi in eq. 2. Similarly, we incremented an addition to mSPN activity in eq. 3 from 0 to 1 arbitrary units, and note that this does not affect daSNCi.
In the analysis plotted in Fig. 2d, we again incremented bsSPN and a similar constant for an mSPN activity addition from 0 to 1 arbitrary units. Here, we computed action values as a multiple of mSPN activity, passed through an activation function, per eqs. 3, 4. The unspecified inputs to the equation (βdirect, cortical input, αj,P) are randomly assigned.
Effect of GPi, LHb, RMTg, and GPe activity on the decision-space
In the analyses plotted in Fig. 2e, f, the activities of the circuit elements are incremented from 0 to 1 arbitrary units in eqs. 2 and 7 and daSNCi in eq. 2 is recorded.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_overview/GPi_LHb_RMTg_DA_model.m.
Effect of sSPN activity on the decision-space
In the analysis plotted in Fig. 3a, we incremented bsSPN in eq. 1 and, for each increment, recorded daSNCi in eq. 2. Then, using the approach in eq. 10, we converted the probability that one decision-dimension is used in the formation of decision-space to the probability that a decision-spaces of a certain dimensionality is formed.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_tests/friedman2015optogeneticmanipulation.m.
Effect of the decision-space on choice
In the analysis plotted in Fig. 3b, we changed which decision-space was formed by mSPNs and measured choice.
The excitation group was modeled using a zero-dimensional decision-space (dopamine→mSPN weights of 0 reward-predominant decision-dimension, 0 cost-predominant dimension). The control group was modeled using a 1D direct pathway decision-space (dopamine→mSPN weights of 0.5 reward-predominant dimension, 0 cost-predominant dimension). The inhibition group was modeled using a 2D direct pathway decision-space (dopamine→mSPN weights of 1 reward-predominant dimension, 1 cost-predominant dimension). The modeled T-maze task was a choice between reward=2, cost=1 (high reward, high cost) and reward=1, cost=0.5 (low reward, low cost). 20 simulations were run per modeled subject for 100 subjects. Other parameters for forming the decision-space and calculating action value are set to their defaults (see Common parameters). For simplicity, the indirect pathway is not modeled in this analysis.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_tests/friedman2015optogeneticmanipulation.m.
In the analysis in Fig. 4b,c, we modeled changes to decision-space and choice after stress.
Here, modeled control rodents made decisions using a 2D direct pathway decision-space formed from reward-predominant and cost-predominant decision-dimensions. This corresponds mathematically to a truncation of βdirect (see eq. 4 and Common parameters) to two columns. The first subset of modeled stress-group rodents made decisions without forming direct pathway decision-space. This corresponds to an elimination of βdirect such that action value is defined purely based on priors (αj,direct in eq. 4). The second subset made decisions without forming direct pathway decision-space until they reached a critical threshold, beyond which they formed a 1D direct pathway decision-space with a reward-predominant dimension. Action values are derived for the three groups across multiple reward and cost combinations (Fig. 4c) via eqs. 3 and 4. Then choices are modeled using eqs. 12, 13, and 15 across 2000 simulations per group for each reward concentration (each incremented from 0 to 1 arbitrary units, 7 increments). Cost concentration is set to 0.5 arbitrary units (set at this level to resemble the steepness of increase in the experimental psychometric function). Default parameters are used for action value formation and the Merton process model. For simplicity, the indirect pathway is not modeled in this analysis. Figure 4b plots the averages of the simulations.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/Friedman2017_lowD_space.m.
In the analysis plotted in Fig. 4d,e, we modeled the effect on choice of shifts in decision-space after a small cost is added to a reward (experimental data is plotted in Supplementary Fig. 4j).
Rodents in the only-reward task were modeled as forming a lower-dimensional direct pathway decision-space (decision-dimension 1 weight = 0.5, decision-dimension 2 weight = 0.2) while animals in the reward-and-cost task formed a higher-dimensional direct pathway decision-space (decision-dimension 1 weight = 1, decision-dimension 2 weight = 0.5).
To do this, we truncated βdirect (see eq. 4 and Common parameters) to two columns or derived action value purely based on priors (αj,direct in eq. 4). A cortical input of reward = 0.7, cost = 0.3 is shown in the plots. For simplicity, the indirect pathway is not modeled in this analysis.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/altered_choice_after_space_transition.m.
In the analysis plotted in Fig. 4h, we modeled changes to choice after aging in young and old groups.
Here, we truncated βdirect (see eq. 4 and Common parameters) to two decision-dimensions, the first corresponding to a reward-predominant decision-dimension and the second corresponding to a cost-predominant decision-dimension. In the current analysis, the first row of βdirect corresponded to licking, while the second row corresponds to performing a different action, e.g. movement. The licking action was assigned a larger prior, \({\alpha }_{1,{{{\rm{direct}}}}}=0,\,{\alpha }_{2,{{{\rm{direct}}}}}=-3\), due to the strong association developed in the rodents between the experimental apparatus and licking. For the modeled “learned, young” group, no decision-space is formed during the reward-cue task and a decision-space using only a cost-predominant decision-dimension is formed during the cost-cue task (i.e. \({{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{reward}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 0\end{array}\right],\,{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{cost}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 1\end{array}\right]\) in eq. 3). For the modeled “learned, old” group, no decision-space is formed during the reward-cue task and a decision-space involving a cost-predominant decision-dimension is partially formed during the cost task \(\left({{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{reward}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 0\end{array}\right],\,{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{cost}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 0.5\end{array}\right]\right)\). For the “not learned” group, a decision-space involving a cost-predominant decision-dimension is partially formed during both tasks \(\left({{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{reward}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 0.5\end{array}\right],\,{{{{\bf{s}}}}}_{{{{\bf{m}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}},{{{\rm{cost}}}},{{{\rm{direct}}}}}=\left[\begin{array}{c}0\\ 0.5\end{array}\right]\right)\). For simplicity, the indirect pathway is not modeled in this analysis.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/Friedman2020_lowD_space.m.
Effect of the decision-space on sSPN-mSPN correlation
In the analysis plotted in Fig. 3d, sSPN-mSPN correlation is compared across decision-spaces with different dimensionality.
It is assumed in the plotted examples that a 1D decision-space is only formed from the first decision-dimension, a 2D decision-space is only formed from the first and the second, and a 3D decision-space is only formed from the first, second, and third. The analysis assumes a comparison of SPNs of the same pathway (that is, either dsSPN-dmSPN or isSPN-imSPN). For this analysis, eigenvalues of cortical activity are set to 2, 1, 0.5, 0.2, and 0.1, respectively. Weighted averages of example signals (left panel) and correlation for different decision-spaces (right panel) are formed using the identity that eigenvalues of principal components are equivalent to their variances.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_tests/ctx_sSPN_mSPN_coordinated_activity.m.
Effect of FSI activity on decision-space
In the analysis plotted in Fig. 4f, we incremented FSI activity aFSI in eq. 5 and determined the response of daSNCi in eq. 2 (a single pathway is considered). The activity parameters related to other circuit elements were held constant (see Common parameters).
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/space_dimensionality_vs_FSI.m.
Effect of cortical SNR on choice
In the analysis plotted in Supplementary Fig. 6a-e, cortical signal to noise ratio (SNR) is altered and the effect on choice is simulated.
Merton process simulations (see Defining choice) are run across ten increments of reward and cost from −1 to 1 arbitrary units for a modeled cost-benefit conflict task. Parameters related to action value are set to their defaults and the T-maze task is used (see Common parameters). Here, “turn right” corresponds to receiving the reward and cost combination, while other actions correspond to receiving no reward and no cost. For simplicity, only the direct pathway is used to influence choice. 100 simulations are run for each of 100 reward and cost combinations, and for each combination, choice is averaged.
The above process is replicated with changes to two sets of parameters. First, the effect of changes to decision-space were considered. A different S in eq. 3 was used depending on specified decision-space: \({{{\bf{S}}}}=\left[\begin{array}{ccc}1 & 0 & 0\\ 0 & 0 & \vdots \\ 0 & \cdots & 0\end{array}\right]\) for 1D decision-spaces, and \({{{\bf{S}}}}=\left[\begin{array}{cc}{{{{\bf{I}}}}}_{{\bf{2}}} & \begin{array}{c}0\\ \vdots \end{array}\\ \begin{array}{cc}0 & \cdots \end{array} & 0\end{array}\right]\) for 2D decision-spaces. Second, changes to cortical noise were considered by adding i.i.d. Gaussian noise to xdirect (with mean 0 and standard deviation σ) at every time step, then recalculating action values in eq. 4 based on the mSPN activities calculated at that time step. Simulations were run for σ = 1,2,…,10. Default parameters were used for calculating action value (see Common parameters).
Examples of single simulations at each level of reward and cost are shown for the σ = 1 (high cortical SNR) and σ = 5 (low cortical SNR) cases in Supplementary Fig. 6a–d. In Supplementary Fig. 6e, expected value is averaged across the 100 simulations for each noise level. Expected value here is defined as reward minus \(0.75 \cdot {{\rm{cost}}}\) (to add preference for reward compared to cost, coefficient is arbitrary) achieved across reward and cost levels. In the plot, SNR is set to the inverse of σ.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/cortical_snr.m.
Effect of dopamine on action/inaction values
In the analyses plotted in Supplementary Fig. 7c–f, we measured the effect of high versus low dopamine on action and inaction values across a range of cortical inputs to the system.
We modeled a cost-benefit conflict task with increasing reward (scale of 0 to 1 arbitrary units, 100 increments) and constant cost (set to 0.25 arbitrary units). Experimental work has shown that dopamine increases direct pathway activity while decreasing indirect pathway activity and vice versa53. Therefore, we set coefficients relating to overall activity of the pathways oppositely: in the low dopamine case, the direct pathway coefficient was 0.1 arbitrary unit and the indirect pathway coefficient 5 arbitrary units; and in the high dopamine case, the indirect pathway coefficient was 5 arbitrary units and the direct pathway coefficient 0.1 arbitrary unit. These coefficients were multiplied by βdirect or βindirect in eq. 4, increasing or decreasing the overall sensitivity of action value on data along cortical principal components. In the model, changes to dopamine also involved a change in decision-space: due to their opposite effects on mSPN activity, dopamine biases the direct pathway towards forming higher-dimensional decision-spaces and the indirect pathway towards forming lower-dimensional decision-spaces. For the purpose of this analysis, eq. 4 is reframed to incorporate the effects of dopamine in scaling action value score (A, set to either 5 or 0.1 arbitrary units in our analysis) and changing decision-space (B, set to 1 arbitrary unit when dopamine is high and 0 when dopamine is low). Here, individual elements are referenced through subscripts based on their jth row and column corresponding to the reward or cost dimension.
\[
\begin{array}{c}{v}_{j,{{{\rm{direct}}}}}=\frac{1}{1+\exp (-A\cdot ({\beta }_{j,{{{\rm{reward}}}},{{{\rm{direct}}}}}+B\cdot {\beta }_{j,{{{\rm{cost}}}},{{{\rm{direct}}}}})-{\alpha }_{j,{{{\rm{direct}}}}})}\end{array}
\]
\[
\begin{array}{c}{v}_{j,{{{\rm{indirect}}}}}=\frac{1}{1+\exp (-A\cdot ((1-B)\cdot {\beta }_{j,{{{\rm{reward}}}},{{{\rm{indirect}}}}}+{\beta }_{j,{{{\rm{cost}}}},{{{\rm{indirect}}}}})-{\alpha }_{j,{{{\rm{indirect}}}}})}\end{array}
\]
where:
- A is the multiplicative effect of dopamine released to mSPNs (dimensionless)
- B is the effect of dopamine on decision-space (dimensionless)
- βj is the connection weight from mSPN to an action value neuron. Each βj,reward or βj,cost corresponds to an element of the connection weight matrix βP.
- priorj is an additive shift corresponding to the neuron encoding action j (activity arb. u.)
The plot in Supplementary Fig. 7c compares the high-dopamine and low-dopamine cases. The plot in Supplementary Fig. 7d shows a similar analysis but for changes in parameters: cost is fixed at 0.5 arbitrary units, and A is set to either 2 arbitrary units (corresponding to the pathway not disconnected) or 0 (corresponding to the pathway disconnected). The plots in Supplementary Fig. 7e, f show progress to action in the case where reward = 1 arbitrary unit and cost = 0.25 arbitrary unit for low versus high dopamine. Deliberation time distributions are formed by aggregating the deliberation times across the 100 simulations. For parameters used for subjective valuation and deliberation time simulation, see Common parameters.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/direct_vs_indirect_pathway_SV.m.
Effect of decision-dimensions on choice
In the analysis plotted in Supplementary Fig. 7i, we altered the connections between mSPN and action/inaction encoding neurons on choice.
A modeled approach/avoid experiment is conducted by offering an option with reward = 1 arbitrary unit, cost = 1 arbitrary unit, and varying (10 values incremented from [0, 2] arbitrary units) physical proximity to another reward. An additional column is added to βdirect and βindirect in eq. 4 to reflect the fact that additional proximity to the other reward increases approach rate: \({{{{\mathbf{\beta }}}}}_{{{{\rm{direct}}}}}={{{{\mathbf{\beta }}}}}_{{{{\rm{indirect}}}}}=\left[\begin{array}{ccc}1 & -1 & 1\\ -1 & 1 & -1\end{array}\right]\), where the upper row corresponds to approaching, the bottom row corresponds to not approaching, and the columns correspond to, from left to right, a reward-predominant decision-dimension, a cost-predominant decision-dimension, and a location-predominant decision-dimension. Reward is assigned a greater relative importance than cost or location (score of 3 arbitrary units versus 1 versus 1) in sSPNs, while cost is assigned a greater relative importance than reward or location (score of 3 arbitrary units versus 1 versus 1). daSNC activity is incremented by changing \({z}_{{{{\rm{daSNC}}}},i,P}\) in eq. 2 for all i and both pathways. Action and inaction values are calculated, and then choice is formed by averaging the results of 1000 Merton process simulations.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/direct_vs_indirect_pathway_proximity_theory.m.
Effects of sSPN, LHb, and daSNC activity on decision-space
In Fig. 6a, bsSPN (eq. 1), \({z}_{{{{\rm{LHb}}}}}\) (eq. 7), and \({z}_{{{{\rm{daSNC}}}},i,P}\) (for all i and a single pathway, eq. 2) are incremented from 0 to 5 arbitrary units with 20 evenly spaced increments along each axis. Each of the 20 × 20 × 20 points are used to derive daSNCi in eq. 2 and converted to decision-spaces via eq. 10.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/day_to_day_space_sampling/decision_space_sampling.py.
Effect of decision-space on choice profiles
In Fig. 6b,e, Supplementary Fig. 8d,f, we form decision-spaces using various decision-dimensions across incremented cortical reward and cost inputs, then classified the action values formed across those reward/cost inputs using a scoring system.
The scoring system, visualized in Supplementary Fig. 8c, is as follows:
Scores for “explore”, “riskiness”, “high action”, “exploit”, “safety”, “low action” are calculated by incrementing reward and cost on [−1 1] (arbitrary units) scales (9 increments are used for each of reward and cost in Fig. 6b, Supplementary Fig. 8d, 6 increments in Fig. 5e, Supplementary Fig. 8f). The notation used here treats vr,c,j as the action value of the jth action at a certain reward and cost increment and vr,c as the set of those action values. In the plotted analysis, k = 4 actions are assigned action values.
To keep with the indexing conventions of the other equations (for instance, eq. 4), we use the index j here to refer to one of the k actions. In the case of eq. 19, where the actions are iterated over twice, we use j1 and j2.
\[
{{{\rm{high}}}}\,{{{\rm{action}}}}={\sum}_{{{{r}}}=-1}^{1} {\sum}_{{{{c}}}=-1}^{1}\left[ {\sum}_{j=1}^{k}{v}_{r,c,j} < 0.2\right]
\]
- Explore. The tendency to pursue multiple actions simultaneously. Scored as the area of the region of reward and cost combinations with a Gini coefficient less than 0.25.
- Exploit. The tendency to pursue only one action. Scored at the area of the region of reward and cost combinations with a Gini coefficient greater than 0.5.
- Riskiness. The combined value of actions when reward and cost are high. Scored by examining the combinations where both reward and cost are greater than 0.
- Safety. The combined value of actions when reward and cost are low. Scored by examining the combinations where both reward and cost are less than 0.
- High action. How often actions will have high action values. Scored as the area of the region of reward and cost combinations that have combined action value greater than 0.5.
- Low action. How often actions will have low action values. Scored as the area of the region of reward and cost combinations that have combined action value less than 0.2.
In the analyses plotted in Fig. 6b and Supplementary Fig. 8d and the examples in Fig. 6c, action value scores, as measured by the scoring definitions above, are compared when different decision-spaces are constructed but cortical input and system parameters are unchanged. The underlying action values across reward and cost levels resembles those from other analyses (see Common parameters) except for an addition of normal random noise (mean = 0, standard deviation = 1) to every element of βdirect (see eq. 4).
The analysis in Supplementary Fig. 8d is similar, except for here, a weighted average is taken of action value scores, as measured by the scoring definitions above, between scenarios where different decision-spaces are constructed. A different S in eq. 3 is used depending on the specified dimensionality of direct pathway decision-space: \({{{\bf{S}}}}=\left[\begin{array}{ccc}1 & 0 & 0\\ 0 & 0 & \vdots \\ 0 & \cdots & 0\end{array}\right]\) for 1D, \({{{\bf{S}}}}=\left[\begin{array}{cc}{{{{\mathbf{I}}}}}_{{\mathbf{2}}} & \begin{array}{c}0\\ \vdots \end{array}\\ \begin{array}{cc}0 & \cdots \end{array} & 0\end{array}\right]\) for 2D, \({{{\bf{S}}}}=\left[\begin{array}{cc}{{{{\bf{I}}}}}_{{\bf{3}}} & \begin{array}{c}0\\ \vdots \end{array}\\ \begin{array}{cc}0 & \cdots \end{array} & 0\end{array}\right]\) for 3D, and S = I4 for 4D. A weighted average of the five decision-spaces is calculated for three levels of sSPN activity (−1, 0, and 1).
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/day_to_day_space_sampling/subjective_value_scores_by_space.m.
In the analyses plotted in Fig. 6e, Supplementary Fig. 8f, for each of 1000 simulations, uncorrelated Gaussian white noise (mean = 0, standard deviation = 1) is added to every element of βdirect (see eq. 4) and 6 by 6 grids of action values across reward and cost combinations are scored by the “explore”, “riskiness”, “high action”, “exploit”, “safety”, and “low action” metrics. Scores for each metric are compared across simulations and between decision-space groups. Observations that score in the top 10% by a metric are considered outliers. Outlier proportion is plotted in Fig. 6e. The means across the simulations of each score are plotted in Supplementary Fig. 8f.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/day_to_day_space_sampling/subjective_value_score_extremes.m.
Instance 2: sparse connectivity and feedforward
In this section, we describe the instance of the model where cortex input to the system does not change over time and the activities of other circuit elements do not decay over time.
This instance of the model leads to a convenient formation of the model as a circuit with no time component. In this section, we frame this instance mathematically and then describe our related analysis. To focus on the portions of the circuit we analyze using this instance, we define here the subset of the circuit involving cortex, FSI, sSPN, daSNC, and mSPN.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/neural_network_model.m.
Cortical input
A set of 4 cortical neurons, notated as C, is sampled at random from a population of 50 cortical neurons. Each neuron in C projects to one FSI and each of q SPNs, which each correspond to a decision-dimension. In our analysis, q is set to 4. This process is repeated 10,000 times per each pathway, forming 10,000 groups of 4 cortical neurons, 1 FSI, 4 dsSPNs (or isSPNs), and 4 dmSPNs (or imSPNs) for each pathway.
Defining FSI activity
FSI activity is defined as a weighted sum of the activities of connected cortical neurons:
\[
{{{{\rm{FSI}}}}}_{C}={\sum}_{q\in C}{w}_{{{{\rm{cortex}}}}\to {{{\rm{FSI}}}}}\,{{{{\rm{cortex}}}}}_{q}+{b}_{{{{\rm{FSI}}}}}
\]
where:
- C is a randomly sampled subset of cortical neurons.
- FSIC is the activity of the FSI which receives projection from the cortical neurons in C (activity arb. u.)
- \({w}_{{{{\rm{cortex}}}}\to {{{\rm{FSI}}}}}\) is the connection weight between cortical neurons and FSIs (dimensionless)
- cortexq is the activity of cortical neuron q (activity arb. u.)
- bFSI affects the relative activity of all sSPN neurons (activity arb. u.)
In the current instance of the model, there are 10,000 FSIs for the direct pathway (projecting to dSPNs) and 10,000 FSIs for the indirect pathway (projecting to iSPNs). Each cortical neuron in C projects to FSIC.
Defining sSPN activity
sSPN activity is defined as a weighted sum of the activities of connected cortical neurons, divided by a weighted sum of the activities of connected FSIs, plus an additive shift bsSPN applied to all sSPNs:
\[
{{{{\rm{sSPN}}}}}_{s,C}=\frac{1}{|C|} {\sum}_{q\in C}\frac{{w}_{q\to s}\,{{{{\rm{cortex}}}}}_{q}}{{{{{\rm{FSI}}}}}_{C}}+{b}_{{{{\rm{sSPN}}}}}
\]
where:
- C is a randomly sampled subset of cortical neurons.
- sSPNs,C is the activity of an sSPN s that receives projection from cortical neurons in C. (activity arb. u.)
- \({w}_{q\to s}\) is the connection weight between cortical neuron q and sSPN s. The weight is equivalent to one of the first four principal components of the cortical activity of the four connected cortical neurons. sSPNs are separated into equal populations that correspond to the first, second, third, or fourth principal component. (dimensionless)
- FSIC is the activity of the FSI which receives projection from the cortical neurons in C (activity arb. u.)
- cortexq is the activity of cortical neuron q (activity arb. u.)
- bsSPN represents the relative activity of all sSPN neurons (activity arb. u.)
In the current instance of the model, there are 40,000 neurons for each of dsSPNs and isSPNs. Activities are defined based on a feedforward network, so the simplification is made that sSPN activities are not affected by daSNC activities. All cortical neurons in C project to sSPNs,C for all s, and similarly, FSIC projects to sSPNs,C for all s.
Defining daSNC activity
The activity of the daSNC element corresponding to decision-dimension i and pathway P is defined by weighted inputs from sSPNs corresponding to decision-dimension i and pathway P:
\[
{{\mathrm{daSNC}}}_{i,P}=\frac{1}{1+\exp\!\Biggl( \frac{1}{n_{{{\mathrm{sSPN}}},i,P}} \sum\limits_{s\in i,P} w_{s\to{{\mathrm{daSNC}}}_{i,P}} {{\mathrm{sSPN}}}_{s}+{{\mathrm{RMTg}}} – z_{{{\mathrm{daSNC}}},i,P}\Biggr)}
\]
where:
- daSNCi,P is the activity the daSNC neuron corresponding to decision-dimension i and pathway P. (activity arb. u.)
- nsSPN,i,P is the count of sSPNs in each of the direct/indirect pathways
- \(w_{s\to{{\mathrm{daSNC}}}_{i,P}}\) is the connection weight from sSPN s to the daSNC neuron corresponding to decision-dimension i and pathway P. The weight is fixed in this instance of the model. (dimensionless)
- sSPNs is the activity of SPN s (activity arb. u.)
- RMTg is RMTg activity (activity arb. u.)
- \({z}_{{{{\rm{daSNC}}}},i,P}\) is the bias in the activity of a daSNC neuron corresponding to decision-dimension i and pathway P. (activity arb. u.)
In the current instance of the model, there are q daSNC neurons that receive projection from the 10,000 dsSPNs corresponding to each decision-dimension, and likewise q daSNC neurons that receive projection from the 10,000 isSPNs corresponding to each decision-dimension. RMTg also projects to all daSNC neurons.
In our analysis using this instance of the model, we arbitrarily set \({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i}=1\) arbitrary unit for both pathways and \({z}_{{{{\rm{daSNC}}}},i}=-\!5\) arbitrary units for all i for the direct pathway, and \({z}_{{{{\rm{daSNC}}}},i}=5\) arbitrary units for all i for the indirect pathway. For simplicity, RMTg is set to 0.
Defining mSPN activity and the decision-space
mSPN activity is defined as a weighted sum of the activities of connected cortical neurons, divided by a weighted sum of the activities of connected FSIs. Here, unlike in the definition of sSPN activity in eq. 26, a di,P term is multiplied to incorporate the weighting of mSPNs by dopamine:
\[
{{{{\rm{mSPN}}}}}_{m,C}=\frac{{d}_{i,P}}{|C|} {\sum}_{q\in C}\frac{{w}_{q\to m}\,{{{{\rm{cortex}}}}}_{q}}{{{{{\rm{FSI}}}}}_{C}}
\]
where:
- C is a randomly sampled subset of cortical neurons
- mSPNm,C is the activity of mSPN m that receives projection from cortical neurons in C (activity arb. u.)
- di,P, which takes the value 0 or 1, is dopamine signaling to mSPNs corresponding to decision-dimension i and pathway P. di,P is the realization of probabilistic weighting of decision-dimensions based on daSNC activity (see Instance 1). (dimensionless)
- \({w}_{q\to m}\) is the connection weight between cortical neuron q and mSPN m. The weight is equivalent to one of the first four principal components of the cortical activity of the four connected cortical neurons. As described in Instance 1, sSPNs are separated into equal populations that correspond to the first, second, third, or fourth principal component. (dimensionless)
- FSIC is the activity of the FSI which receives projection from the cortical neurons in C (activity arb. u.)
- cortexq is the activity of cortical neuron q (activity arb. u.)
In the current instance of the model, there are 40,000 neurons for each of dmSPNs and imSPNs All cortical neurons in C project to mSPNm,C for all m, and similarly, FSIC projects to mSPNm,C for all m.
Modeling SPN encoding of data, using Instance 2
To explore the ability of SPNs to successfully encode data along decision-dimensions, even when cortex and SPNs are sparsely connected, we constructed networks with different degrees of dimensionality reduction (Supplementary Fig. 5g). A single pathway is considered. One type of network had 2 times dimensionality reduction (20 cortical neurons, 10 SPNs), another had 10 times dimensionality reduction (100 cortical neurons, 10 SPNs), and another had 100 times dimensionality reduction (1000 cortical neurons, 10 SPNs), similar to what is found in the human brain67,68.
For each type, we constructed modeled networks with cortex→SPN connections equal to principal components of cortical activity by simulating, for each analyzed pathway, a random symmetric positive definite matrix that is used as the cortical covariance matrix \({{{{\mathbf{\Sigma }}}}}_{{{P}}}\) (see Defining sSPN activity) via MATLAB’s sprandsym() with density=1. Eigenvalues are arbitrarily specified as λ1 = 2, λ2 = 2, λ3 = 0.5, λ4 = 0.2, and λ5 = λ6 = … = λP = 0, i.e. the first and second principal components are very important, the third somewhat important, the fourth slightly important, and the others unimportant. The weights WP from cortical neurons to the q SPN circuit elements per pathway are then derived as the first q eigenvectors of \({{{{\mathbf{\Sigma }}}}}_{{{P}}}\).
We incremented the number of cortical neurons that connected to each SPN from 2 to 10. The network was connected sparsely based on the specified number of connections from randomly selected cortical neurons to each SPN. For simplicity in this analysis, we created a cortical signal that resembled the first principal component of cortical activity as a whole (regardless of connectivity to SPNs) and let the first cortical principal component to have large eigenvalue compared to the others (i.e. λ1 = 1, λ2 = 0.1, λ3 = λ4 = … = λP = 0).
For each of the modeled networks (3 network types by 9 increments from 2 to 10), we simulated the process 1000 times. During each simulation, we calculated the ability of the network to discriminate between the large signal along the first cortical principal component and the absence of signal along the second cortical principal component, given its access to only a subset (2 to 10 cortical neurons) of the complete signal.
Then the SPNs encoding data along the first versus second decision-dimension were assessed in their ability to distinguish between signals along the first cortical principal component versus the second. This was quantified using the Bhattacharyya distance of the activity among SPNs encoding data along the first decision-dimension versus the second, assuming the subpopulations have mean activities μ1 and μ2 and standard deviations σ1 and σ2, respectively.
\[
{D}_{B}=\frac{1}{4}\frac{{({\mu }_{1}-{\mu }_{2})}^{2}}{{\sigma }_{1}^{2}+{\sigma }_{2}^{2}}+\frac{1}{2}\,{{\mathrm{ln}}}(\frac{{\sigma }_{1}^{2}+{\sigma }_{2}^{2}}{2{\sigma }_{1}{\sigma }_{2}})
\]
where:
- μ1 is the mean activity of activities in the first subpopulation (activity arb. u.)
- μ2 is the mean activity of activities in the second subpopulation (activity arb. u.)
- σ1 is the standard deviation of activities in the first subpopulation (activity arb. u.)
- σ2 is the standard deviation of activities in the second subpopulation (activity arb. u.)
For the current analysis, aFSI is arbitrarily set to 1 arbitrary unit and bFSI is arbitrarily set to 0.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/dimension_discrimination_vs_sparsity.m.
Instance 3: full connectivity and dynamics
In this section, we describe the instance of the model where each cortical neuron projects to each FSI, each FSI projects to each SPN (for dsSPN, isSPN, dmSPN, imSPN), and each cortical neuron projects to each SPN.
This instance of the model leads to a convenient formation of the model as a circuit of fewer elements (one FSI, one dsSPN, isSPN, dmSPN, and imSPN per the four decision-dimensions), with a time component. In this section, we frame this instance mathematically and then describe our related analysis.
To focus on the portions of the circuit we analyze using this instance, we define here the subset of the circuit involving cortex, sSPN, daSNC, and mSPN.
Defining SPN and daSNC activity
Here, the activities of SPN and daSNC elements and the weights from sSPN to daSNC are represented as a system of differential equations. Because FSI activity is not measured in the related analyses, cortical activity to pathway P after FSI normalization xi,P(t) is used as input to the system in the equations below.
For a model diagram, see Fig. 5a. Note that daSNC activity of 0 (i.e. average activity) leads to 0 change in SPN activity (due to the 1/2 terms in eqs. 30 and 31. Changes to GPe activity are not modeled here, so the equations are simplified to exclude GPe.
\[
\begin{array}{c}\tau \cdot \frac{{{{\rm{d}}}}{s}_{{{{\rm{sSPN}}}},i,P}(t)}{{{{\rm{d}}}}t}=\,-{s}_{{{{\rm{sSPN}}}},i,P}(t)+{x}_{i,P}(t)-{w}_{{{{\rm{daSNC}}}}\to {{{\rm{sSPN}}}},i,P}\cdot ({y}_{{{{\rm{sSPN}}}},i,P}(t)-\frac{1}{2})\end{array}
\]
\[
\begin{array}{c}\tau \cdot \frac{{{{\rm{d}}}}{s}_{{{{\rm{mSPN}}}},i,P}(t)}{{{{\rm{d}}}}t}=-{s}_{{{{\rm{mSPN}}}},i,P}(t)+{x}_{i,P}(t)+{w}_{{{{\rm{daSNC}}}}\to {{{\rm{mSPN}}}},i,P}\cdot ({y}_{{{{\rm{sSPN}}}},i,P}(t)\,-\frac{1}{2})\end{array}
\]
\[
\begin{array}{c}\frac{{{{\rm{d}}}}}{{{{\rm{d}}}}t}{w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}(t)=\kappa \cdot {s}_{{{{\rm{sSPN}}}},i,P}(t)\end{array}
\]
where:
\[
\begin{array}{c}{y}_{{{{\rm{sSPN}}}},i,P}(t)=\frac{1}{1+\exp ({w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}(t)\cdot {s}_{{{{\rm{sSPN}}}},i,P}(t)+{{{\rm{RMTg}}}}-{z}_{{{{\rm{daSNC}}}},i,P})}\end{array}
\]
- τ is the time constant related to the decay rate of activity (dimensionless)
- Si,P(t) is the SPN activity (either dsSPN, isSPN, dmSPN, or imSPN) corresponding to decision-dimension i and pathway P, as a function of time. (activity arb. u.)
- t is time (seconds)
- xi,P(t) is the cortical activity input, after FSI normalization, to an SPN corresponding to decision-dimension i and pathway P (activity arb. u.)
- \(\begin{array}{c}{w}_{{{{\rm{daSNC}}}}\to {{{\rm{sSPN}}}},i,P}\end{array}\) is the connection weight from a daSNC neuron corresponding to decision-dimension i and pathway P to an sSPN (either dsSPN or isSPN) corresponding to decision-dimension i and pathway P (dimensionless)
- yi,P(t) is the activity of the daSNC neuron corresponding to decision-dimension i and pathway P, as a function of time (activity arb. u.)
- \(\begin{array}{c}{w}_{{{{\rm{sSPN}}}}\to {{{\rm{daSNC}}}},i,P}(t)\end{array}\) is the connection weight from an sSPN (either dsSPN or isSPN) to a daSNC neuron corresponding to decision-dimension i and pathway P, as a function of time (dimensionless)
- \(\kappa\) is a coefficient that determines the rate at which the connection from sSPNs to daSNC neurons changes depending on sSPN (dsSPN or isSPN) activity (dimensionless)
- \({z}_{{{{\rm{daSNC}}}},i,P}\) is the bias in the activity of a daSNC neuron corresponding to decision-dimension i and pathway P (activity arb. u.)
- RMTg is the output of RMTg, per eq. 7 (activity arb. u.)
In the current instance of the model, there are q dsSPNs, q isSPNs, q dmSPNs, q imSPNs, q daSNC neurons that each receive projection from a dsSPN, and q daSNC neurons that each receive projection from an isSPN. daSNC neurons corresponding to decision-dimension i and pathway P project to sSPNs and mSPNs of the same i and P.
Defining the decision-space
A decision-dimension is used to form the decision-space at times when daSNC activity corresponding to the decision-dimension exceeds a threshold:
\[
{{{{\bf{S}}}}}_{{i},{P}}(t)=\left\{\begin{array}{cc}0 & {y}_{i,P}(t) < {{{\rm{threshold}}}}\\ 1 & {y}_{i,P}(t)\ge {{{\rm{threshold}}}}\end{array}\right.
\]
where:
- yi,P(t) is the activity of the daSNC neuron corresponding to decision-dimension i and pathway P, as a function of time. (activity arb. u.)
- Si,P(t) is the application of dopamine release (via daSNC activity) to mSPN activity corresponding to decision-dimension i and pathway P. The notation here is used to match the notation in Instance 1; Si,P(t) is the (i,i) element of the diagonal matrix SP(t) whose elements correspond to the weights assigned to the decision-dimensions, similar to in eq. 3. (dimensionless)
Defining action value
Action value is defined here like in Instance 1, except mSPN activity (for dmSPN and imSPN) is defined as a function of time:
\[
{v}_{j,P}=\frac{1}{1+\exp (-{{{{\mathbf{\beta }}}}}_{j,P}\,{{{{\bf{s}}}}}_{{{{\bf{mSPN}}}},P}(t)-{\alpha }_{j,P})}
\]
where:
- βj,P is a matrix of weights from dmSPNs to downstream action value encoding neurons for the direct pathway, or imSPNs to downstream inaction value encoding neurons for the indirect pathway (dimensionless)
- ssSPN,P is the activity of sSPNs corresponding to decision-dimension i and pathway P (activity arb. u.)
- t is time (seconds)
- αj,P is an additive shift corresponding to the neuron encoding action j for the direct pathway or inaction j for the indirect pathway (activity arb. u.)
As in the other instances of the model, there is one neuron encoding each vj,P. So, there are k neurons encoding action values and k neurons encoding inaction values. Each of these neurons receives projections from all mSPNs of the corresponding pathway.
Modeling time-variant input, using Instance 3
In Fig. 5d-i, simulated responses of dsSPN, isSPN, dmSPN, and imSPN are derived using the forward Euler method with step size 0.001 s.
In Fig. 5d,e, the cortical input to sSPN elements corresponding to each of four example direct pathway decision-dimensions is represented by a vector of length 5001 (corresponding to 0 s to 5 s with increments 0.001 s). Four arbitrary input vectors are used, one corresponding to each plotted decision-dimension:
\[
2+\sin (t),\,1+\cos (t),\,\sin (2t),\,\cos (2t)
\]
The first vector corresponds to a reward-predominant dimension (shown in green in Fig. 5i). A relatively large positive average value (2 arbitrary units) is assigned to it as an example of an important decision-dimension to a decision. A cost-predominant decision-dimension (second vector) is specified to be important, but less so, and novelty-predominant and location-predominant decision-dimensions (third and fourth vectors) are assigned to be relatively unimportant. The number of decision-dimensions used to form decision-space is averaged across time steps in the 5 s simulation. In d, simulations are run across 100 evenly spaced increments of an addition to each vector at all timesteps. In e, simulations are run across 100 evenly spaced increments of \({z}_{{{{\rm{daSNC}}}},i}\) (for each pathway, depending on the simulation) in eq. 7 from −1 to 1 arbitrary units.
Figure 5f, g show examples of the response of dsSPN, isSPN, dmSPN, and imSPN elements to different cortical inputs. In Fig. 5f, a cortical input of 10 arbitrary units for 2.5 s is followed by an input of 20 arbitrary units for 2.5 s. In Fig. 5g, a cortical input of 10 arbitrary units for 2.5 s is followed by an input of 0 for 2.5 s.
In the analysis shown in Fig. 5h, cortical inputs of 10 arbitrary units for 2.5 s are followed by cortical inputs with prediction errors incremented by 0.1 from −1 to arbitrary units. These prediction errors are relative to the original cortical input of 10 arbitrary units. For example, for the prediction error of −1, there is a signal of 0 for 2.5 s, and for the prediction error of 1, there is a signal of 20 for 2.5 s. To find the change in the activities of circuit elements, their activities at 2.5 s are subtracted from their activities at 5 s.
Figure 5i shows simulations for an example input with \(\kappa=0\) in eq. 32 versus \(\kappa=0.1\) arbitrary units. The cortical input is as follows: in decision-dimension 1 (e.g. reward-predominant), a cortical signal of 10 arbitrary units for the 0-1.23 s timeframe and elsewhere a signal of 0; in decision-dimension 2 (e.g. cost-predominant), a cortical signal of 10 arbitrary units for the 1.25-2.43 s timeframe and elsewhere a signal of 0; in decision-dimension 3, a cortical signal of 10 arbitrary units for the 2.5-3.73 s timeframe and elsewhere a signal of 0; and in decision-dimension 4, a cortical signal of 10 arbitrary units for the 3.75-5 s timeframe and elsewhere a signal of 0.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/dynamic_model_and_neural_net/sSPN_DA_mSPN_dynamic_interaction.m.
Parameters are set to common values, chosen arbitrarily, with physiologically accurate signs:
- in eqs. 30, 31: τ = 1
- in eq. 30: \({w}_{{{{\rm{daSNC}}}}\to {{{\rm{sSPN}}}},{{{\rm{direct}}}}}=-1\)
- in eq. 30: \({w}_{{{{\rm{daSNC}}}}\to {{{\rm{sSPN}}}},{{{\rm{indirect}}}}}=1\)
- in eq. 31: \({w}_{{{{\rm{daSNC}}}}\to {{{\rm{mSPN}}}},{{{\rm{direct}}}}}=1\)
- in eq. 31: \({w}_{{{{\rm{daSNC}}}}\to {{{\rm{mSPN}}}},{{{\rm{indirect}}}}}=-1\)
- in eq. 32: \(\kappa=-0.01\)
- in eq. 33: RMTg = 0
- in eq. 33: \({z}_{{{{\rm{daSNC}}}},i,P}=0\) for all i and P
- in eq. 34: threshold = 0.5
Additionally, the following initial conditions, also chosen arbitrarily, are used across analyses:
- \({s}_{{{{\rm{sSPN}}}},i,{{{\rm{direct}}}}}(0)={s}_{{{{\rm{sSPN}}}},i,{{{\rm{indirect}}}}}(0)={s}_{{{{\rm{mSPN}}}},i,{{{\rm{direct}}}}}(0)={s}_{{{{\rm{mSPN}}}},i,{{{\rm{indirect}}}}}(0)=0\)
- \({w}_{{{{\rm{sSPN}}}} \to {{\rm{daSNc}}},i,{{{\rm{direct}}}}}(0)={w}_{{{{\rm{sSPN}}}} \to {{{\rm{daSNc}}}},i,{{{\rm{indirect}}}}}(0)=1\)
Shifts in the decision-space in a reinforcement learning task
Here, we run simulations in a Reinforcement Learning (RL) environment to compare the decision-space model with a traditional model of reinforcement learning in the basal ganglia. In a traditional model, dopamine signals RPEs, whereas in the decision-space model, it conveys the decision-space (Fig. 6b). To compare the models, we record RPEs during a very simple RL task and compare it with times at which the decision-space is likely to shift.
Constructing the RL task
In the task, an agent moves from a starting position (referred to here as a “state” to align with standard RL terminology) to an intermediate state where it can move left or right to receive one of the two cost/reward outcomes, and then moves to receive one of the outcomes. The agent learns over the course of 20 episodes via a classical Q-learning algorithm (for reinforcement learning foundation, see Supplementary Note 9). Q-values are updated based on the Bellman equation, simplified to exclude the values of future states (because we examine values at outcome state):
\[
V({s}_{t})=V({s}_{t})+\alpha \cdot [{r}_{t}-V({s}_{t})]
\]
where:
- V(St) is the value of the current state St.
- α is the learning rate (set arbitrarily to 0.5).
- rt is the reward or cost received in St.
The exploration rate is arbitrarily set to 0.5, and otherwise the strategy is epsilon-greedy. That is, the agent approaches left 25% of the time, right 25% of the time, and 50% of the time chooses the direction it has assigned to the highest Q-value to.
Using the same notation, the RPE at timestep t, δt, is the difference between the reward observed and the Q-value (note that similar to the formula above, the values of future states have been excluded because we measure RPEs at terminal states):
\[
{\delta }_{t}={r}_{t}-V({s}_{t})
\]
Recording choice over a T-maze RL simulation
In the simulation plotted in Supplementary Fig. 7k, the agent moves through the simple RL-environment. When the agent reaches one of the two terminal states (for either reward/cost outcome), the Q-value of the outcome is updated per eq. 37. In the simulation, for the first 10 episodes, the agent receives +1 reward for approaching right and −1 reward for approaching left. Then for the final 10 episodes, the agent receives −1 reward for approaching right and +1 reward for approaching left.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/importance_and_RPEs/Tmaze_RL.py.
Comparing RPEs with episodes when a shift in the decision-space might occur
In Supplementary Fig. 7l, RPEs are compared with shifts in the decision-space that might occur were a rodent to perform the task. The analysis is performed using the same simulation as in Supplementary Fig. 7k.
RPEs are calculated per eq. 38. The episodes corresponding to likely sudden “shifts” in the decision-space, as plotted, follow the rules:
- A reward decision-dimension is used, and only used, when a reward appears.
- A cost decision-dimension is used, and only used, when a cost appears.
- If a reward (or cost) is expected, then there is no sudden “shift” into using that decision-dimension because such a shift will have occurred earlier than the outcome state.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/importance_and_RPEs/Tmaze_RL.py.
Movement of circuit activity across multiple trials
Here, we model changes in circuit activity between trials. We begin by forming advantage and cost functions that guide the realignment of the circuit. Using these, we explore how vulnerability versus resilience in disorder formation could be interpreted through the lens of the model.
Defining advantage and cost of circuit activity
‘Advantage’ is defined here as the ability of the circuit to produce beneficial decision-spaces at a certain activity. The goal of the sSPN→GPi→LHb→RMTg→daSNC circuit in the model is to produce preferred decision-spaces for action valuation (Fig. 6a–d). For instance, in a laboratory environment when an animal routinely makes a choice to approach depending on reward level, a one-dimensional direct pathway decision-space with a reward dimension may be helpful. During a decision, it may make sense for this animal to reach a circuit activity where forming a one-dimensional direct pathway decision-space is probable.
We represent this logic mathematically as a function of an n-element circuit \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\). In our analysis, we focus on either FSI and sSPN, holding the rest of the circuit elements fixed at default values (see Common parameters); or sSPN, LHb, and daSNC, holding the rest of the circuit elements fixed at default values. The advantage of a certain circuit activity is defined as a weighted sum of probabilities the direct pathway decision-space occurs and the benefit of forming each decision-space:
\[
{{{\rm{advantage}}}}({X}_{1}={x}_{1},\,{X}_{2}={x}_{2},\ldots,{X}_{n}={x}_{n})={\sum}_{l=1}^{{2}^{q}}{{{{\rm{score}}}}}_{l}\cdot \\ {{{\rm{P}}}}({{{{\rm{space}}}}}_{l}|({X}_{1}={x}_{1},\,{X}_{2}={x}_{2},\ldots,{X}_{n}={x}_{n}))
\]
where:
- \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\) are elements of the circuit with activities \({x}_{1},{x}_{2},\ldots,{x}_{n}\) (activity arb. u.)
- q is the count of decision-dimensions
- scorel is a coefficient corresponding to the preference for a given direct pathway decision-space (dimensionless)
- The probability each decision-space forms is derived from probability its decision-dimensions individually are used during the decision (daSNCi in eq. 2, here notated as di):
The rationale for this formation of advantage is theoretical. Elsewhere, we show that direct pathway decision-spaces of different dimensionality are beneficial (and may be used by rodents) for tasks of different difficulties (Fig. 3). We also show that certain decision-spaces are beneficial with certain levels of cortical noise (Supplementary Fig. 6) and for obtaining different types of action values (Fig. 6c–f). We represent this as an assignment of greater value to certain decision-spaces, given external and internal contexts and the task at hand.
‘Cost’, here, is defined as the difference between the circuit activity and a baseline activity. For most scenarios, the circuit might be best served searching for the circuit activity with the highest advantage. However, there is an obvious counterexample: it could be that it is easiest to form preferred decision-spaces at extremely unusual circuit activity (e.g. very high sSPN, very high LHb, very high daSNC), and only slightly more difficult to form that decision-space at closer to average circuit activity (average sSPN, low LHb, average daSNC). It may be more advantageous for the circuit to shift to the latter activity.
Therefore, we introduce a cost function to form ‘net advantage’. We then use net advantage to define the circuit activities that are the most beneficial. The concept of baseline circuit activity is introduced here in order to define cost. This can be interpreted as the circuit activity outside of decision-making.
\[
{{\mathrm{cost}}} (X_1= x_1,\;X_2=x_2,\;\ldots,\;X_n=x_n)= \bigl\| [\,x_1\;x_2\;\ldots\;x_n\,]^{{\mathrm{T}}} \\ -[\,x_{1,{{\mathrm{baseline}}}}\;x_{2,{{\mathrm{baseline}}}}\;\ldots\;x_{n,{{\mathrm{baseline}}}}\,]^{{\mathrm{T}}}\bigr\|
\]
where:
- \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\) are elements of the circuit with activities \({x}_{1},{x}_{2},\ldots,{x}_{n}\) (activity arb. u.)
- Outside of decision-making, \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\) have baseline activities \({x}_{1,{{{\rm{baseline}}}}},{x}_{2,{{{\rm{baseline}}}}},\ldots,{x}_{n,{{{\rm{baseline}}}}}\) (activity arb. u.)
Net advantage is defined as advantage minus cost multiplied by a constant:
\[
{{\mathrm{net}}}\;{{\rm{advantage}}}(X_{1}=x_{1},\ldots,X_{n}=x_{n})= \;{{\mathrm{advantage}}}(X_{1}=x_{1},\ldots,X_{n}=x_{n})\\ -{{\mbox{constant}}}\,\cdot\,{{\mbox{cost}}}(X_{1}=x_{1},\ldots,X_{n}=x_{n})
\]
where:
- Functions for reward and cost are taken from eqs. 39 and 41, respectively
- \({{\rm{constant}}}\) alters the weight given to cost compared to reward (dimensionless)
Visualizing advantage, cost, and net advantage
Figure 7b shows an example of how a circuit forms advantage per eq. 39. The advantage scores scorei are randomly generated (normal distribution, mean 0, standard deviation 1) for each of the 16 possible decision-spaces formed from four decision-dimensions. sSPN and daSNC activity are incremented across a 10×10 grid of sSPN and daSNC activities which each range from 0 to 10 arbitrary units. The activities of other circuit elements are set to default values in Instance 1 of the model (see Common parameters).
Cost in Fig. 7c is formed using eq. 41. Distance from the circuit baseline point is measured as Euclidean distance in the two plotted decision-dimensions.
Net advantage in Fig. 7d is calculated per eq. 42. For this example, the cost coefficient constant = 1 (dimensionless coefficient).
Figure 7f similarly shows net advantage but after incrementing sSPN, LHb, and daSNC activities. Similar to in the example in Fig. 7d, a set of scores are independently randomly generated and constant in eq. 42 is set arbitrarily to 1 (dimensionless coefficient).
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/circuit_trajectories/advantage_cost_net_advantage_example.m.
Defining direction of circuit movement
The direction of movement is defined as a search for the optimal circuit activity to produce advantageous direct pathway decision-spaces. To understand how a circuit governed by eq. 42 might adjust over the course of multiple trials, we relate the adjustment of circuit activity to net advantage. We specify that the circuit adjusts so that it can more easily reach advantageous decision-spaces. This constitutes a movement in the baseline activity of eq. 42.
Thus, the circuit adapts in the direction of the gradient of net advantage.
\[
\frac{\Delta \,{[{x}_{1,{{{\rm{baseline}}}}}{x}_{2,{{{\rm{baseline}}}}}\ldots {x}_{n,{{{\rm{baseline}}}}}]}^{{{{\rm{T}}}}}}{{{{\rm{trial}}}}}={{{\rm{rate}}}}\cdot \nabla {{{\rm{net}}}}\,{{{\rm{advantage}}}}({X}_{1}={x}_{1},\ldots,{X}_{n}={x}_{n})
\]
where:
- \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\) are elements of the circuit with activities \({x}_{1},{x}_{2},\ldots,{x}_{n}\) (activity arb. u.)
- Outside of decision-making, \(\{{X}_{1},{X}_{2},\ldots,{X}_{n}\}\) have baseline activities \({x}_{1,{{{\rm{baseline}}}}},{x}_{2,{{{\rm{baseline}}}}},\ldots,{x}_{n,{{{\rm{baseline}}}}}\) (activity arb. u.)
- rate is a coefficient that affects the speed of movement of the circuit per trial (trial-1)
Effect of initial circuit activity on future trials
In Fig. 7e, g, Supplementary Fig. 9a, several examples illustrate trajectories of circuit movement, as defined in eq. 43.
In these analyses, we assume that decision-dimensions are assigned equal importance by sSPN (i.e. in eq. 1, bsSPN = 0). The probability that an individual decision-dimension is used to form decision-space is calculated using eq. 2. Advantage scores scorei are randomly generated (normal distribution, mean = 0, standard deviation = 1 arbitrary unit) for each of the 16 possible decision-spaces created from four dimensions. The value of constant in eq. 42 is set to 1 arbitrary unit. For each increment of a 15 × 15 grid of sSPN and FSI (Fig. 7e) or 15 × 15 × 15 grid of sSPN, LHb, and daSNC (Fig. 7g, Supplementary Fig. 9a), net advantage is calculated for the scenario where that activity is the circuit baseline, i.e. \({X}_{1}={x}_{1,{{{\rm{baseline}}}}},{X}_{2}={x}_{2,{{{\rm{baseline}}}}},\ldots,{X}_{n}={x}_{n,{{{\rm{baseline}}}}}\). The gradient of this grid is approximated via MATLAB’s gradient() routine. Trajectories are integrated from the gradient via MATLAB’s streamline(), which uses the forward Euler method.
In the upper panel of Fig. 7e, circuit baseline points are shown for each increment of Euler’s method. The bottom panel shows the trajectories of 20 randomly selected points on the [0, 5] arbitrary units range for sSPN and FSI.
In Fig. 7g, starting points are selected to form a 5 × 5 × 5 grid incremented along sSPN, LHb, and daSNC axes. At each point in a trajectory line, the probability a dimension is used to form decision-space is calculated via eq. 2. Then, during plotting, these calculated probabilities are interpolated using MATLAB’s patch() routine.
In Supplementary Fig. 9a, the gradient is plotted using MATLAB’s streamslice(). Then the trajectories of five randomly selected are plotted.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/circuit_trajectories/sSPN_DA_LH_trajectories.m and https://github.com/dirkbeck/DM_space_model/blob/main/circuit_trajectories/sSNC_DA_LH_trajectories_examples2.m.
Effect of altered advantage score on future trials
In Supplementary Fig. 9b, c, we examine the effect of a change to advantage scorel in eq. 39 as a modeled task is being performed.
The circuit adjusts over 100 trials. At the beginning, advantage score is set to 1 (dimensionless coefficient) for the non-D decision-space and 0 for every other decision-space. Over the first 20 and the last 10 time-steps (between the dashed lines on the plots), advantage score is incremented for the 4D decision-space but not others. Over time steps 21-90, advantage score is incremented for the non-D decision-space.
In the plot, the value of each decision-space is divided by the total value of all decision-spaces to form a ratio.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/circuit_trajectories/changing_space_value_between_trials.m.
Reasoning behind the FSI model
In eq. 1, scaling of cortical data serves the important functional role of normalizing xP so that the circuit can make sense of data coded across the wide range of firing rates that might be observed in the cortex (Supplementary Fig. 2a; for a discussion of the experimental literature, see Supplementary Note 10). Per the experimental literature reviewed in Supplementary Note 10, many cortical neurons synapse to one FSI and the cortical to FSI connection is excitatory. Physiological analysis of connected FSI and cortical neurons in the current work shows that FSI activity scales linearly with cortical activity (Supplementary Fig. 4k, l).
In the model, the parameter aFSI is related to the strength of connection between cortex and FSI. The parameter bFSI is related to firing rate of FSI when xP = 0.
The algebraic operator that best represents this inhibition is less clear: it could be thought of as a subtraction or as a division depending on the experimental evidence used to model (for a discussion of the experimental literature, see Supplementary Note 10).
A subtraction possibility:
\[
{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}({a}_{{{{\rm{FSI}}}}})={{{{\bf{x}}}}}_{P}-{a}_{{{{\rm{FSI}}}}}
\]
A division possibility:
\[
{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}({a}_{{{{\rm{FSI}}}}})=\frac{{{{{\bf{x}}}}}_{P}}{{a}_{{{{\rm{FSI}}}}}}
\]
where:
- aFSI is the weight of cortex→FSI connection (dimensionless)
- xP is the activities of the cortical neurons in a given pathway P (activity arb. u.)
The analytic relationship used here leads to a convenient interpretation from the perspective of data processing. It can also be thought of as approximating subtraction or division depending on the scale of aFSI. Below, we show a series approximations of eq. 1 as a function of connection strength from cortex, with input from cortex and other parameters fixed.
Substitution in terms of aFSI:
\[
{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}({a}_{{{{\rm{FSI}}}}})=\frac{1}{{a}_{{{{\rm{FSI}}}}}\cdot {\Vert {{{{\bf{x}}}}}_{P}\Vert }_{2}+{b}_{{{{\rm{FSI}}}}}}{{{{\bf{x}}}}}_{P}{{{\bf{W}}}}+{b}_{{{{\rm{sSPN}}}}}
\]
Truncated Taylor series at aFSI = 0:
\[
\begin{array}{c}{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}({a}_{{{{\rm{FSI}}}}})={{{{\bf{b}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}+\frac{{{{{\bf{x}}}}}_{P}{{{\bf{W}}}}}{{b}_{{{{\rm{FSI}}}}}}-\frac{{\Vert {{{{\bf{x}}}}}_{P}\Vert }_{2}\,{{{{\bf{x}}}}}_{P}{{{\bf{W}}}}}{{{b}_{{{{\rm{FSI}}}}}}^{2}\,}\cdot {a}_{{{{\rm{FSI}}}}}+{{{\mathscr{O}}}}({{a}_{{{{\rm{FSI}}}}}}^{2})\end{array}
\]
Truncated Laurent series at \({a}_{{{{\rm{FSI}}}}}=\infty\):
\[
\begin{array}{c}{{{{\bf{s}}}}}_{{{{\bf{s}}}}{{{\bf{S}}}}{{{\bf{P}}}}{{{\bf{N}}}}}({a}_{{{{\rm{FSI}}}}})={b}_{{{{\rm{sSPN}}}}}+\frac{{{{{\bf{x}}}}}_{P}{{{\bf{W}}}}}{{\Vert {{{{\bf{x}}}}}_{P}\Vert }_{2}}\cdot \frac{1}{{a}_{{{{\rm{FSI}}}}}}-{{{\mathscr{O}}}}(\frac{1}{{{a}_{{{{\rm{FSI}}}}}}^{2}})\end{array}
\]
Thus, when FSI is weakly connected to cortex, the formula somewhat resembles a subtractive operation, and when FSI is strongly connected to cortex, the formula somewhat resembles a division operation. The ratio between the aFSI and bFSI parameters is important here (the first series, before truncation, converges when \(\frac{|{b}_{{{{\rm{FSI}}}}}|}{{a}_{{{{\rm{FSI}}}}}} > {\Vert {{{{\bf{x}}}}}_{P}\Vert }_{2}\) and the second, before truncation, when \(\frac{|{b}_{{{{\rm{FSI}}}}}|}{{a}_{{{{\rm{FSI}}}}}} < {\Vert {{{{\bf{x}}}}}_{P}\Vert }_{2}\)).
Inferring decision-space from SPN activity and choice
The decision-space can be inferred from environmental or experimental inputs in conjunction with decision-making data (Supplementary Fig. 2q, r). The method here requires that many decision-making experiments have been run with a similar apparatus but different parameters (for instance, light level), and that average sSPN activity has been measured during the decisions. The parameter data is stored in a matrix \({{{\bf{X}}}}\in {{\mathbb{R}}}^{n\times p}\), where n here is a separate trial with separate inputs (rather than different inputs across time steps, as in the description of Instance 1) and P is the number of features of the experiment that may be encoded by cortex, for instance temperature, music volume, or light level (similar to the description in Instance 1).
The process involves three steps:
Labeling sessions
Recorded decisions are labeled using attributes of the process by which the decision was made. This might be achieved in a rodent task that measures response to music volume, for instance, by clustering sessions based on heart rate and distance traveled.
Constraints based on SPN activity
The sessions are split by label. X is standardized such that each column has a mean of 0 and standard deviation 1. Then a linear regression is run on each labeled subset Xl to find coefficients bl that map those observations to predicted SPN activities (averaged across SPN decision-dimensions) \({\hat{{{{\bf{y}}}}}}_{l}\) for each session in the subset (here, the subscript l is used to indicate all elements of the subset):
\[
{\hat{{{{\bf{y}}}}}}_{l}={{{{\bf{X}}}}}_{l}{{{{\bf{b}}}}}_{l}+{b}_{0}
\]
where:
- \({\hat{{{{\bf{y}}}}}}_{l}\) is predicted SPN activities
- Xl is a subset of experimental parameter data corresponding to one label
- bl and b0 are the linear regression coefficients that map the experimental parameters to sSPN activity
From the calculated bl, we can guess the principal axis dimensions that make up decision-space \({{{\bf{w}}}_{1}},{{{\bf{w}}}_{{\bf{2}}}}, \ldots ,{{{\bf{w}}}_{q}}\) and the presence of each decision-dimension \({{e}_{li}} \in \{0,1\}\) in each labeled subset. During this process, we consider bl as the sum of the dimensions in decision-space in the subset:
\[
{{\mathbf{b}}}_{l}={\sum}_{i=1}^{q} e_{l,i}\,{{\mathbf{w}}}_{i}
\]
Using this framework, we can form a rule which we can use to assign labels to decision-dimensions and hypothesize \({{{{\bf{w}}}}}_{1},{{{{\bf{w}}}}}_{{{{\bf{2}}}}},{{\mathrm{..}}}.,{{{{\bf{w}}}}}_{q}\):
If bA has high correlation with bB, then one of bA or bB must correspond to a higher-dimensional decision-space that also includes the dimensions of the other.
For example, we might have data with labels A, B, C, and D and corresponding \({{{{\bf{b}}}}}_{A},{{{{\bf{b}}}}}_{B},{{{{\bf{b}}}}}_{{{{\boldsymbol{C}}}}},{{{{\bf{b}}}}}_{D}\), where bA is correlated with bD, bB is correlated with bD, and the other possible pairs uncorrelated. It follows from the rule above that bD is at least a two-dimensional decision-space including dimensions from bA and bB, and that bA and bB are at least one-dimensional decision-spaces. So, we would hypothesize that there are two SPN-encoded decision-dimensions used during the decision, w1 and w2, and that subsets A and D use w1, subsets B and D use w2, and subset C does not use either.
The logic to construct these constraints are as follows. When \({e}_{l1}={e}_{l2}={{\mathrm{..}}}.={e}_{lq}=0\) (i.e. a zero-dimensional decision-space), \({\hat{{{{\bf{y}}}}}}_{l}={b}_{0}\). The coefficients assigned to the zero-dimensional decision-space \({{{{\bf{b}}}}}_{l:\,0{{{\rm{D}}}}\,{{{\rm{space}}}}}\) should have low correlation with any of the axes \({{{{\bf{w}}}}}_{1},{{{{\bf{w}}}}}_{{{{\bf{2}}}}},\ldots,{{{{\bf{w}}}}}_{q}\). Therefore, it is expected that we find one bl that has low correlation with the other bl, and we can label this \({{{{\bf{b}}}}}_{l:\,0{{{\rm{D}}}}\,{{{\rm{space}}}}}\). Further, when eli for one i is equal to 1 and for all other i is equal to 0 (i.e. a 1D decision-space), \({\hat{{{{\bf{y}}}}}}_{l}={{{{\bf{w}}}}}_{i\,{{{\rm{in}}}}\,{{{\rm{space}}}}}+{b}_{0}\). This decision-space will have high correlation with \({{{{\bf{w}}}}}_{i\,{{{\rm{in}}}}\,{{{\rm{space}}}}}\) but low correlation with other wi. Therefore, it is expected that we find several \({{{{\bf{b}}}}}_{l:\,\dim i\,{{{\rm{space}}}}}\) that are not correlated with one another, or \({{{{\bf{b}}}}}_{l:\,0{{{\rm{D}}}}\,{{{\rm{space}}}}}\), but may be related through the multi-dimensional decision-spaces in subset C. Finally, when eli is equal to 1 for multiple i, bl is calculated as a sum per eq. 50. Therefore, it is expected that some \({{\mathbf{b}}}_{l:\,\dim i \ \cap \ \dim j \, {{\rm{ space}}}}\) are linear combinations of \({{{{\bf{b}}}}}_{l:\,\dim i\,{{{\rm{space}}}}}\) and \({{{{\bf{b}}}}}_{l:\,\dim j\,{{{\rm{space}}}}}\).
The example shown in Supplementary Fig. 2r uses simulated data with 2 experimentally observed features (for instance, temperature and music volume) and 100 observations. X was constructed as a matrix of i.i.d. Gaussian variables with mean 0 and standard deviation 1. The ground-truth principal component matrix W was constructed as a 2 × 2 matrix of i.i.d. Gaussian variables with mean 0 and standard deviation 1. Then, for each of the 100 observations, a decision-space was randomly assigned in a reference dataset. Each decision-dimension for each observation was treated as an i.i.d. uniform variable, and if the variable corresponding to the observation and the decision-dimension exceeded a value (here, 0.5), then the dimension was considered as incorporated in decision-space. The randomly generated decision-spaces were each assigned their own label. Then a simulated SPN activity was created for each of the 100 observations was created by multiplying the ground-truth W by the decision-space used in each observation, similar to in eq. 1. i.i.d. Gaussian noise (mean 0, standard deviation 0.5) was then added to create simulated SPN activity observations. Using this simulated data, we ran a linear regression for each labeled subset via MATLAB’s fitlm() routine. The linear regression fits are plotted as surfaces in Supplementary Fig. 2r. The slopes, with respect to temperature and music volume, were, for label A, −0.15 and 0.48, respectively; for label B, −437.90 and −9.72, respectively; for label C, −9.01 and −274.51, respectively; and for label D, −155.45 and −199.83. Slopes for label A are relatively small, so it is assigned to “decision-space not formed” (matching the reference dataset). Of the remaining labels, label D is closer to an additive combination of labels B and C than other permutations, so label D is assigned the “2D decision-space” (matching the reference dataset), while labels B and C are each considered 1D decision-spaces (matching the reference dataset).
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_overview/dimensionality_from_SPN_activity.m.
Tests using choice
We can then combine the constraints in Step 2, developed using SPN activity, with an analysis of choice given the hypothesized SPN-encoded decision-dimensions. In Step 2, a set of \({{{{\bf{w}}}}}_{{{1}}},{{{{\bf{w}}}}}_{{{2}}},\ldots,{{{{\bf{w}}}}}_{{{q}}}\) are hypothesized. Here, choice at different levels of those wi are compared across the labeled subsets. The hypothesis in Step 2 is supported if choice, for each labeled subset, is correlated with the decision-dimensions hypothesized to be used to form decision-space but not correlated with the decision-dimensions hypothesized not to be used to form decision-space.
An example is shown in Supplementary Fig. 2r. For the case where decision-space is not formed, choices do not correlate with any hypothesized SPN-encoded decision-dimension. For a 1D decision-space, choices correlate with one hypothesized SPN-encoded decision-dimension. For a 2D decision-space, choices correlate with two hypothesized SPN-encoded decision-dimensions.
In the plotted examples, we plot simulated choices in each of the four decision-spaces used in the analysis. Choices are simulated from reference dataset (i.e. absent noise added during simulation) average sSPN activities by session y by treating \(Z=\frac{1}{1+\exp (-y+{{{\rm{i}}}}.{{{\rm{i}}}}.{{{\rm{d}}}}.\,{{{\rm{Gaussian}}}}\,{{{\rm{noise}}}})}\) as a random variable, where Z < 0.5 corresponds to a “turn left” action and \(Z\ge 0.5\) to a “turn right” action. The threshold of 0.5 is chosen because it represents the expected value of Z at average sSPN activity (y = 0). In the plots, we interpolate possible subject values from choice at different combinations of the two decision-dimensions w1 and w2, as derived in Step 2. For each action for each labeled subset, a logistic regression is used to convert actions to the value of the action across the grid. As expected, observations of label A, assigned to “decision-space not formed” have little correlation with either of the putative decision-dimensions derived in Step 2; observations of labels B and C, assigned to 1D decision-spaces, are correlated with one putative decision-dimension but not the other; and observations of label D, assigned to the “2D decision-space,” are correlated with both.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/model_overview/dimensionality_from_SPN_activity.m
Testing the model through analysis of neural data
As a further test of the decision-space model, we examined the relationships between behavior and neural activity in tasks that required different reward versus cost dimensions. The analysis, new to the current work, was performed using the Corticostriosomal Circuit Stress Experiment database (published with Friedman et al., 2017). We found more functionally connected sSPN and mSPN in tasks that were difficult. We then analyzed cortex, FSI, sSPN, and mSPN during these tasks and found evidence of dimensionality reduction from cortical neurons to SPNs.
Defining decision difficulty by task
We defined decision difficulty through deliberation time, calculated as the time between when the door opened during the T-maze task and when the animal made a movement between one end of the maze or the other. Deliberation time distributions were analyzed for each trial group (for control and stress: cost-benefit cost, benefit-benefit, cost-cost, non-conflict cost-benefit). Skewness was calculated using MATLAB’s skewness() routine. Example distributions are shown in Supplementary Figs. 3b, 4a, b (6 animals, 35 sessions) and summaries across groups in Supplementary Figs. 3d, 4c, d (14 rats, 249 sessions).
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/Cross%20Correlation%20Pattern%20Counts/createPaperFigures.m.
Fitting the modeled deliberation times
To replicate the deliberation time distributions with a computational model, we leveraged a diffusion model where two functions would both start at zero and would continue towards either a positive or negative pre-defined threshold that represented either performing an action (positive threshold) or not performing an action (negative threshold). The first threshold that was reached by either function was which decision we considered as selected. The x-axis was the progression of time as the functions ran. The deliberation time for this model was the amount of time (in seconds) it took for the first function to reach its threshold. To match the experimental distribution times analyzed in Supplementary Fig. 3b, we ran the drift diffusion process adjusting drift rate, the thresholds, and noise until the modeled deliberation time distribution had a similar median and skew to experimental data from Supplementary Fig. 3c (10.7910/DVN/SMKW0I). An additional 1.5 seconds was uniformly added to modeled distribution times.
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/Cross%20Correlation%20Pattern%20Counts/createPaperFigures.m.
Connected SPNs through cross-correlation
We used the Corticostriosomal Circuit Stress Experiment database to identify sSPN and mSPN among recorded neurons in the striatum. For details, see the Supplemental Materials & Methods of Friedman et al. (2017). 14785 cells across 14 control animals were analyzed. The total number of identified striosomal and matrix neurons per task: NCB = non-conflict cost-benefit (14 sSPNs, 260 mSPNs), CC = cost-cost (46 sSPNs, 400 mSPNs), CBC = cost-benefit conflict (84 sSPNs, 717 mSPNs), BB = benefit-benefit easy (50 sSPNs, 515 mSPNs, chocolate milk concentration <50), BB = benefit-benefit difficult (33 sSPNs, 731 mSPNs, chocolate milk concentration >=50).
We binned the firing rates of sSPN and mSPN during the −3s to 3 s window across all tasks into 1-5 bins. We used these firing rates to determine cross-correlation (MATLAB’s xcorr()) between sSPN and mSPN recorded in the same session. Correlated pairs were defined as paired sSPN and mSPN that had a linear regression fit with correlation squared (MATLAB’s corrcoef()) > 0.5 and significance p < 0.04. To obtain the percentage of significantly correlated neurons, we counted the number of pairs that met the threshold for correlation and divided by the total number of identified pairs. Examples are plotted in Supplementary Fig. 3e,f and counts in Supplementary Fig. 3g.
To determine the significance threshold for the counts of correlated pairs, we shuffled the sSPN and mSPN pairs across the database. We then performed the process above on the shuffled data. Using these shuffled pairs, we formed a distribution of correlations that might happen by chance. The threshold of significance was set to the 3 standard deviation mark among this distribution of shuffled pairs.
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/Cross%20Correlation%20Pattern%20Counts/runMe.m.
Connected SPNs through Granger causality
sSPN and mSPN pairs were identified similarly to the previous section. 14785 cells across 14 control animals were analyzed, and 25758 cells across 9 stress animals. The total identified number of striosomal and matrix cells for each of the tasks is the following: Control CC = cost-cost (46 sSPNs, 400 mSPNs), Control BB = benefit-benefit (83 sSPNs, 1246 mSPNs), Control CBC = cost-benefit conflict (84 sSPNs, 717 mSPNs), Stress CBC = cost-benefit conflict (41 sSPNs, 898 mSPNs, Stress BB = benefit-benefit (156 sSPNs, 2813 mSPNs).
Then firing rates were determined over the span of the session by binning each trial into bins of 100 ms. Granger causality (MATLAB’s gctest()) was run on these sSPN and mSPN firing rate pairs to determine whether each pair was functionally connected. In control animals, 92 connected pairs were identified for the cost-benefit conflict task, 77 connected pairs for the cost-cost task, 1 connected pair for the non-conflict cost-benefit task, and 116 pairs for the benefit-benefit task. In stress animals, 110 connected pairs were identified for the cost-benefit conflict task and 292 connected pairs for the benefit-benefit task.
Next, for each of the trials with a functionally connected sSPN and mSPN pair, the class of motif was determined as either sSPN excited / mSPN excited, sSPN excited / mSPN inhibited, sSPN inhibited / mSPN excited, or sSPN inhibited / mSPN inhibited. These classes were formed by identifying whether, separately, the neurons were excited, inhibited, or neither in each of 5 blocks per each trial ([−15s, −3s], [−3s 0 s], [0 s 2.5 s], [2.5 s, 4.5 s], [4.5 s 20 s]). A motif was counted if, in a certain block, each neuron was either excited or inhibited.
Excited or inhibited classifications were determined through inter-spike interval analysis, plotted in Supplementary Fig. 3h-j. The median inter-spike interval for each neuron across the full trial was calculated. A neuron was considered inhibited during the periods of the trial when the inter-spike interval exceeded the median. Conversely, a neuron was considered excited during periods when the inter-spike interval fell below median. Excited blocks were defined as blocks where excitation time exceeded inhibition time by 10%. Inhibited blocks were defined, oppositely, as blocks where inhibition time exceeded excitation time by 10%. Blocks that reached neither threshold were not classified.
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/Cross%20Correlation%20Pattern%20Counts/createPaperFigures.m.
Analyzing neural dimensionality reduction
In the analysis plotted in Fig. 3f, using data from the Corticostriosomal Circuit Stress Experiment database, we analyzed firing rates of 1) PL neurons that project to striatum (i.e. sSPN-projecting cortex, 221 sessions, 2-47 neurons per session), 2) FSIs (96 sessions, 2-12 neurons per session), 3) sSPNs (27 sessions, 2-9 neurons per session), and 4) mSPN (13 sessions, 2-6 neurons per session). For methods of classification, see Friedman et al. (2017). Spike data was converted to firing rates by separating the spikes into 5-10 bins.
Covariance between the neurons was determined from the firing rates of simultaneously recorded neurons over time. For each trial, the effective correlation49 was calculated from the activities of the p neurons over time:
\[
{{{\rm{effective}}}}\,{{{\rm{correlation}}}}=1-{\Vert {{{\rm{Corr}}}}(X)\Vert }^{1/p}
\]
Effective correlations were then averaged across trials. Confidence intervals were determined from standard error between the sessions. p-values were calculated using a two-sample t-test (MATLAB’s ttest2 routine).
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/neuron_pair_analysis/run_me.m.
Changes to choice after adding cost to a reward offer
In the analysis plotted in Supplementary Fig. 4j, we sought to define choice patterns before and after stress when a small cost was added to a reward offer. To do this, we analyzed choice data from the CBC task before and after stress (i.e. reward and a small cost) and in the BB task before and after stress (i.e. only reward). We recorded the approach percentage across sessions and then averaged these between groups. Data from 17 rodents across 38 sessions is used for Control CBC, data from 13 rodents across 24 tasks for Stress CBC, data from 23 rodents across 114 tasks for Control BB, and data from 14 rodents across 116 tasks for Stress BB.
For data, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/experimental_data_analysis_choice_before_after_stress.xlsx.
Analyzed cortex-FSI connectivity
Using data from the Corticostriosomal Circuit Stress Experiment database (published with Friedman et al. (2017)), firing rates of striatum-projecting prelimbic cortex neurons (i.e. sSPN-projecting cortex) and FSIs were analyzed. For details regarding neuron classification, see Friedman et al. (2017). Spike data was converted to firing rates by separating data into 5-10 bins. A linear regression of the form a x + b was fit through the firing rates. Examples are plotted in Supplementary Fig. 4k, l and averages of the square of Pearson correlation coefficient across neuron pairs and the a slope parameter from the regression fit are plotted in Supplementary Fig. 4o, p. 78 neuron pairs across 7 rodents were analyzed before stress and 37 neuron pairs were analyzed across 4 rodents after stress.
For instructions to run code, see https://github.com/dirkbeck/DM_space_model/blob/main/neuron_pair_analysis/run_me.m.
Modeled cortex-FSI connectivity after stress
Connected cortical neurons and FSI show increased correlation and reduced slopes between their firing rates after stress (Supplementary Fig. 4k, l, o, p). To understand how this impacts SPNs, we modeled two changes to the cortex→FSI connectivity that might produce the experimental results (Supplementary Fig. 4q, r). A first factor, connection weight wq, measured the strength of connection between the qth connected cortical neuron and the FSI, that is, how strongly FSI would respond to an increase in activity in the connected cortical neuron. A second factor, number of connections c, measured the number of connected cortical neurons to the FSI.
We solved for correlation between the neurons and slope using identities that link covariance, correlation, and slope. This process assumes that FSI receives input only from the cortex.
Note that, to align with the indexing used in Instance 2 (e.g. eq. 25), we use the index q for cortical neurons. In eq. 55, we use q1 and q2 to refer to different cortical neurons.
\[
\begin{array}{c}{{{\rm{correlation}}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})=\frac{{{\mathrm{cov}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})}{\sqrt{{{\mathrm{var}}}({{{\rm{cortex}}}}\,1)\cdot {{\mathrm{var}}}({{{\rm{FSI}}}})}}\end{array}
\]
\[
\begin{array}{c}{{{\rm{slope}}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})=\frac{{{\mathrm{cov}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})}{{{\mathrm{var}}}({{{\rm{FSI}}}})}\end{array}
\]
\[
{{\mathrm{cov}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})={w}_{1}{{\mathrm{var}}}({{{\rm{cortex}}}}\,1)+{\sum}_{q=2}^{c}{w}_{q}\cdot {{{\rm{cov}}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{cortex}}}}\,q)
\]
\[
{{\mathrm{var}}}({{{\rm{FSI}}}})={\sum}_{q=1}^{c}{{w}_{q}}^{2}{{\mathrm{var}}}({{{\rm{cortex}}}}\,q)+{\sum}_{{q}_{1}=1}^{c} {\sum}_{{{q}_{2}=1} \atop {{q}_{1}\ne {q}}_{2}}^{c}{w}_{{q}_{1}}{w}_{{q}_{2}}{{\mathrm{cov}}}({{{\rm{cortex}}}}\,{q}_{1},\,{{{\rm{cortex}}}}\,{q}_{2})
\]
For simplicity, we assumed in our analysis that variance is equal across cortical neurons projecting to the FSI (i.e. \({{{\rm{var}}}}({{{\rm{cortex}}}}\,1)={{{\rm{var}}}}({{{\rm{cortex}}}}\,2)=\ldots={{{\rm{var}}}}({{{\rm{cortex}}}}\,c)\)) and that the covariance between those neurons is equal (i.e. \({{{\rm{cov}}}}({{{\rm{cortex}}}}\,1,{{{\rm{cortex}}}}\,q)={{{\rm{cov}}}}({{{\rm{cortex}}}}\,1,{{{\rm{cortex}}}}\,2)={{{\rm{cov}}}}({{{\rm{cortex}}}}\,1,{{{\rm{cortex}}}}\,3)=\ldots={{{\rm{cov}}}}({{{\rm{cortex}}}}\,1,{{{\rm{cortex}}}}\,c)\)). So, in the analysis plotted in Supplementary Fig. 4q, r, we substitute uniform variance and covariance to obtain:
\[
\begin{array}{c}{{{\rm{correlation}}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})=\sqrt{\frac{{{\mathrm{var}}}({{{\rm{cortex}}}}\,1)+(c-1)\cdot {{\mathrm{cov}}}({{{\rm{cortex}}}}\,1,{{{\rm{cortex}}}}\,q)}{c\cdot {{\mathrm{var}}}({{{\rm{cortex}}}}\,1)}}\end{array}
\]
\[
\begin{array}{c}{{{\rm{slope}}}}({{{\rm{cortex}}}}\,1,\,{{{\rm{FSI}}}})=\frac{1}{cw}\end{array}
\]
where:
- c is the number of cortex neurons connected to each FSI
- w is the weight of each cortex→FSI connection
Thus, changes in strength of connection may be more likely to affect slope, while changes in the quantity of connections, the covariance between cortical neurons, and the variance of cortical neurons may also affect the cortex to FSI correlation. In stress, correlation is larger while slope is reduced, suggesting reduction in quantity of cortex to FSI connections.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/ctx_to_FSI_synchrony_analysis.m.
Simulation illustrating the theoretical change
We then conducted a simulation to examine the case where cortical data and cortex to FSI connectivities were less uniform. To do this, we constructed a network with random unit normal connection weights from cortex to FSI. Then we randomly lesioned all but several of the connections to reflect the sparsity of the brain. The connection from the first cortical neuron to the FSI was always preserved.
In each of ten simulations, a cortical input to sSPN was generated as a random unit normal 100 × 1 vector. Activity of the first cortical neuron and the FSI was recorded. These are plotted in Supplementary Fig. 4m, n along with a linear regression fit.
For code, see https://github.com/dirkbeck/DM_space_model/blob/main/disorder_hypotheses/ctx_to_FSI_synchrony_analysis.m.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Supplementary Materials
Supplementary Materials
References
- RL Aupperle, MP Paulus. Neural systems underlying approach and avoidance in anxiety disorders. Dialogues Clin. Neurosci., 2010. [PubMed]
- JR Crittenden, AM Graybiel. Basal Ganglia disorders associated with imbalances in the striatal striosome and matrix compartments. Front Neuroanat., 2011. [PubMed]
- A Friedman. Chronic stress alters striosome-circuit dynamics, leading to aberrant decision-making. Cell, 2017. [PubMed]
- AM Graybiel, A Matsushima. Striosomes and matrisomes: scaffolds for dynamic coupling of volition and action. Annu. Rev. Neurosci., 2023. [PubMed]
- AB Nelson, AC Kreitzer. Reassessing models of basal ganglia function and dysfunction. Annu Rev. Neurosci., 2014. [PubMed]
- J Cox, IB Witten. Striatal circuits for reward learning and decision-making. Nat. Rev. Neurosci., 2019. [PubMed]
- AM Graybiel, CW Ragsdale. Histochemically distinct compartments in the striatum of human, monkeys, and cat demonstrated by acetylthiocholinesterase staining. Proc. Natl Acad. Sci. USA, 1978. [PubMed]
- KR Brimblecombe, SJ Cragg. The Striosome and Matrix Compartments of the Striatum: A Path through the Labyrinth from Neurochemistry toward Function. ACS Chem. Neurosci., 2017. [PubMed]
- CR Gerfen. Synaptic organization of the striatum. J. Elec. Microsc. Tech., 1988
- A Friedman. Striosomes mediate value-based learning vulnerable in age and huntington’s model. Cell, 2020. [PubMed]
- A Friedman. A corticostriatal path targeting striosomes controls decision-making under conflict. Cell, 2015. [PubMed]
- B Bloem. Multiplexed action-outcome representation by striatal striosome-matrix compartments detected with a mouse cost-benefit foraging task. Nat. Commun., 2022. [PubMed]
- M Weglage. Complete representation of action space and value in all dorsal striatal pathways. Cell Rep., 2021. [PubMed]
- X Xiao. A Genetically Defined Compartmentalized Striatal Direct Pathway for Negative Reinforcement. Cell, 2020. [PubMed]
- T Yoshizawa, M Ito, K Doya. Reward-predictive neural activities in striatal striosome compartments. eNeuro, 2018
- 16.Lazaridis, I. et al. Striosomes control dopamine via dual pathways paralleling canonical basal ganglia circuits. Curr. Biol. S0960982224013381 10.1016/j.cub.2024.09.070 (2024).
- TA Jenrette, JB Logue, KA Horner. Lesions of the patch compartment of dorsolateral striatum disrupt stimulus-response learning. Neuroscience, 2019. [PubMed]
- JA Nadel. Optogenetic stimulation of striatal patches modifies habit formation and inhibits dopamine release. Sci. Rep., 2021. [PubMed]
- JA Nadel, SS Pawelko, D Copes-Finke, M Neidhart, CD Howard. Lesion of striatal patches disrupts habitual behaviors and increases behavioral variability. PLoS One, 2020. [PubMed]
- EM Prager. Dopamine Oppositely Modulates State Transitions in Striosome and Matrix Direct Pathway Striatal Spiny Neurons. Neuron, 2020. [PubMed]
- RC Evans. Functional dissection of basal ganglia inhibitory inputs onto substantia nigra dopaminergic neurons. Cell Rep., 2020. [PubMed]
- S Hong. Predominant Striatal Input to the Lateral Habenula in Macaques Comes from Striosomes. Curr. Biol., 2019. [PubMed]
- N Rajakumar, K Elisevich, BA Flumerfelt. Compartmental origin of the striato-entopeduncular projection in the rat. J. Comp. Neurol., 1993. [PubMed]
- F Fujiyama. Exclusive and common targets of neostriatofugal projections of rat striosome neurons: a single neuron-tracing study using a viral vector. Eur. J. Neurosci., 2011. [PubMed]
- A Nambu, H Tokuno, M Takada. Functional significance of the cortico–subthalamo–pallidal ‘hyperdirect’ pathway. Neurosci. Res., 2002. [PubMed]
- 26.Schroll, H. & Hamker, F. H. Computational models of basal-ganglia pathway functions: focus on functional neuroanatomy. Front. Syst. Neurosci. 7, (2013).
- 27.Bahuguna, J., Verstynen, T. & Rubin, J. E. How cortico-basal ganglia-thalamic subnetworks can shift decision policies to maximize reward rate. Preprint at 10.1101/2024.05.21.595174 (2024).
- B Millidge, Y Song, A Lak, ME Walton, R Bogacz. Reward Bases: A simple mechanism for adaptive acquisition of multiple reward types. PLoS Comput Biol., 2024. [PubMed]
- 29.Humphries, M. D. The Computational Bottleneck of Basal Ganglia Output (and What to Do About it). eNeuro12, e0431 (2025).
- J Song, H Lin, S Liu. Basal ganglia network dynamics and function: Role of direct, indirect and hyper-direct pathways in action selection. Netw.: Comput. Neural Syst., 2023
- K Dunovan, B Lynch, T Molesworth, T Verstynen. Competing basal ganglia pathways determine the difference between stopping and deciding not to go. eLife, 2015. [PubMed]
- E Wärnberg, A Kumar. Feasibility of dopamine as a vector-valued feedback signal in the basal ganglia. Proc. Natl Acad. Sci. USA., 2023. [PubMed]
- P Calabresi, B Picconi, A Tozzi, V Ghiglieri, M Di Filippo. Direct and indirect pathways of basal ganglia: a critical reappraisal. Nat. Neurosci., 2014. [PubMed]
- G Barbera. Spatially Compact Neural Clusters in the Dorsal Striatum Encode Locomotion Relevant Information. Neuron, 2016. [PubMed]
- M Azcorra. Unique functional responses differentially map onto genetic subtypes of dopamine neurons. Nat. Neurosci., 2023. [PubMed]
- JR Crittenden. Striosome-dendron bouquets highlight a unique striatonigral circuit targeting dopamine-containing neurons. Proc. Natl Acad. Sci. USA, 2016. [PubMed]
- ML Wallace. Genetically Distinct Parallel Pathways in the Entopeduncular Nucleus for Limbic and Sensorimotor Output of the Basal Ganglia. Neuron, 2017. [PubMed]
- GR Christoph, RJ Leonzio, KS Wilcox. Stimulation of the lateral habenula inhibits dopamine-containing neurons in the substantia nigra and ventral tegmental area of the rat. J. Neurosci.: Off. J. Soc. Neurosci., 1986
- S Hong, TC Jhou, M Smith, KS Saleem, O Hikosaka. Negative Reward Signals from the Lateral Habenula to Dopamine Neurons Are Mediated by Rostromedial Tegmental Nucleus in Primates. J. Neurosci., 2011. [PubMed]
- AK Lahiri, MD Bevan. Dopaminergic Transmission Rapidly and Persistently Enhances Excitability of D1 Receptor-Expressing Striatal Projection. Neurons Neuron, 2020. [PubMed]
- S Grillner, B Robertson. The basal ganglia downstream control of brainstem motor centres—an evolutionarily conserved strategy. Curr. Opin. Neurobiol., 2015. [PubMed]
- 42.Balleine, B. W., Delgado, M. R. & Hikosaka, O. The Role of the Dorsal Striatum in Reward and Decision-Making. 5.
- HJ Lee. Activation of direct and indirect pathway medium spiny. Neurons Drives Distinct. Brain-wide Responses Neuron, 2016. [PubMed]
- TSY Ho, S Lee. Term structure movements and pricing interest rate contingent claims. J. Financ., 1986
- R Ratcliff, G McKoon. The Diffusion Decision Model: Theory and Data for Two-Choice Decision Tasks. Neural Comput., 2008. [PubMed]
- DM Herz. Dynamic control of decision and movement speed in the human basal ganglia. Nat. Commun., 2022. [PubMed]
- TD Sanger. Optimal unsupervised learning in a single-layer linear feedforward neural network. Neural Netw., 1989
- J Kamiński. Novelty-Sensitive Dopaminergic Neurons in the Human Substantia Nigra Predict Success of Declarative Memory Formation. Curr. Biol., 2018. [PubMed]
- S Kim, AK Bera. Scalar Measures of Volatility and Dependence for the Multivariate Models with Applications to Asian Financial Markets. JRFM, 2023
- 50.Classical Microeconomics. in On Classical Economics 48–78 (Yale University Press, 2017). 10.12987/9780300185669-005.
- G Winterer, DR Weinberger. Genes, dopamine and cortical signal-to-noise ratio in schizophrenia. Trends Neurosci., 2004. [PubMed]
- Y Miyamoto, S Katayama, N Shigematsu, A Nishi, T Fukuda. Striosome-based map of the mouse striatum that is conformable to both cortical afferent topography and uneven distributions of dopamine D1 and D2 receptor-expressing cells. Brain Struct. Funct., 2018. [PubMed]
- O Hikosaka. Direct and indirect pathways for choosing objects and actions. Eur. J. Neurosci., 2019. [PubMed]
- M Maltese, JR March, AG Bashaw, NX Tritsch. Dopamine differentially modulates the size of projection neuron ensembles in the intact and dopamine-depleted striatum. Elife, 2021. [PubMed]
- AG Salinas, MI Davis, DM Lovinger, Y Mateo. Dopamine dynamics and cocaine sensitivity differ between striosome and matrix compartments of the striatum. Neuropharmacology, 2016. [PubMed]
- Z Luo, ND Volkow, N Heintz, Y Pan, C Du. Acute Cocaine Induces Fast Activation Of D1 Receptor And Progressive Deactivation Of D2 Receptor Striatal Neurons: In Vivo Optical Microprobe [Ca2+]i Imaging. J. Neurosci., 2011. [PubMed]
- K Oyama, I Hernádi, T Iijima, K-I Tsutsui. Reward prediction error coding in dorsal striatal neurons. J. Neurosci., 2010. [PubMed]
- P Cavedini. Decision-making heterogeneity in obsessive-compulsive disorder: ventromedial prefrontal cortex function predicts different treatment outcomes. Neuropsychologia, 2002. [PubMed]
- SE Cohen, JB Zantvoord, BN Wezenberg, CLH Bockting, GA Van Wingen. Magnetic resonance imaging for individual prediction of treatment response in major depressive disorder: a systematic review and meta-analysis. Transl. Psychiatry, 2021. [PubMed]
- S Saperia. Modeling effort-based decision making: individual differences in schizophrenia and major depressive disorder. Biol. Psychiatry.: Cogn. Neurosci. Neuroimaging, 2023. [PubMed]
- AGC Wright, LJ Simms. Stability and fluctuation of personality disorder features in daily life. J. Abnorm. Psychol., 2016. [PubMed]
- ASS de Siqueira. Decision Making assessed by the Iowa Gambling Task and Major Depressive Disorder A systematic review. Dement Neuropsychol., 2018. [PubMed]
- J Cousijn. Individual differences in decision making and reward processing predict changes in cannabis use: a prospective functional magnetic resonance imaging study. Addict. Biol., 2013. [PubMed]
- SR Horn, A Feder. Understanding Resilience and Preventing and Treating PTSD. Harv. Rev. Psychiatry, 2018. [PubMed]
- CL Pickens, SA Golden, T Adams-Deutsch, SG Nair, Y Shaham. Long-lasting incubation of conditioned fear in rats. Biol. Psychiatry, 2009. [PubMed]
- I Fredriksson. Orbitofrontal cortex and dorsal striatum functional connectivity predicts incubation of opioid craving after voluntary abstinence. Proc. Natl Acad. Sci. U.S.A., 2021
- I Bar-Gad, G Morris, H Bergman. Information processing, dimensionality reduction and reinforcement learning in the basal ganglia. Prog. Neurobiol., 2003. [PubMed]
- H Bergman. Physiological aspects of information processing in the basal ganglia of normal and parkinsonian primates. Trends Neurosci., 1998. [PubMed]
- T Truong. Corticostriosomal Circuit Stress Experiment. Mendeley, 2017
- 70.Beck, D. W. et al. Computational model of striosomal circuit in normal and disordered decision-making. 2148949671, 222497 Harvard Dataverse 10.7910/DVN/SMKW0I (2024).
- 71.Dirk Beck & Luis David Davila. A decision-space model explains context-specific decision-making. Zenodo 10.5281/ZENODO.15433188 (2025).